1.
Принцип работы поисковых систем. 6
2. Основные поисковые системы. 18
2.1.
Глобальные поисковые системы. 18
AltaVista
(http://www.altavista.com/) 18
Ask
Jeeves (http://www.ask.com/) 19
Excite
(http://www.exclte.com/) 19
FAST
Search (http://www.alltheweb.com/) 19
Go/Infoseek
(http://www.go. com/) 19
Google
(http://www.google.com/) 20
HotBot
(http://hotbot.lycos.com/) 20
Lycos
(http://www.lycos.com/) 20
Yahoo!
(http://www.yahoo.com/) 21
2.2.
Российские поисковые системы. 21
Апорт
(http://www.aport.ru/) 21
Rambler
(http://www.rambler.ru/) 22
Яndex
(http://www.yandex.ru/) 22
WebAlta
(http://www.webalta.ru ) 22
3.1.
Правила составления запросов к поисковым машинам. 23
3.2.
Запросы, обрабатываемые всем поисковыми машинами одинаково 24
Запросы,
использующие расстояние между словами. 26
Поиск
по странам и регионам. 26
Поиск
по типам файлов (фильтр) 26
Поиск
по дате модификации файла. 26
Обработка
регистров букв в запросе. 27
3.3.
Язык запроса глобальных поисковых систем. 28
AltaVista
(http://www.altavista.com) 28
AllTheWeb
(FAST Search) (http://www.alltheweb.com) 34
Google
(http://www.google.com) 38
Yahoo!
(http://www.yahoo.com) 45
3.4.
Язык запроса русских поисковых систем. 48
Апорт
(http://www.aport.ru) 48
Rambler
(http://www.rambler.ru) 57
Яndex
(http://www.yandex.ru) 66
4.1.
Типовые структуры размещения информации на Web-узле и возможности навигации 77
4.2.
Логика "третьего" уровня и приемы применения автоматических поисковых
средств. 79
4.3.
Язык запросов ЯndexSite. 84
AltaVista (http://www.altavista.com/) 91
Ask Jeeves
(http://www.ask.com/) 95
Excite
(http://www.exclte.com/) 97
FAST Search
(http://www.alltheweb.com/) 99
Google (http://www.google.com/) 100
Lycos
(http://www.lycos.com/) 104
Yahoo! (http://www.yahoo.com/) 105
Go/Infoseek (http://www.go. com/) 108
Hot Bot
(http://www.hotbot.com) 109
Яndex (http://
www.yandex.ru/) 111
Рамблер
(http://www.rambler.ru/) 114
Апорт (http://
www.aport.ru/) 116
ВебАльта (http://
www.webalta.ru/) 119
Современный мир уже немыслим без понятия Internet (Интернет). Каждая уважающая себя компания обязательно имеет свой сайт, где располагается информация о самой компании, об ее деятельности и возможности связи. Через Интернет совершаются покупки, осуществляются заказы билетов на самолет и бронирование мест в гостинице. Зарегистрировать установленную программу, получить обновление, обратиться к разработчикам, все это обусловлено теми действительно полезными возможностями, которые предоставляет Интернет.
За время существования сети в ней накоплен огромный объем знаний в электронном виде. Этой большое достоинство и в то же время недостаток Интернет. Пополнение информационных ресурсов Интернета происходит высокими темпами, и найти необходимую информацию становиться всё труднее. Различные печатные справочники устаревают ещё до выхода в свет. Единственным надёжным способом поиска информации является использование различных поисковых систем, которые постоянно отслеживают изменение информации в сети.
Учебное пособие предназначено для пользователей, имеющих навыки работы с компьютером.
В первом разделе рассматриваются принципы работы поисковых систем,
приводится их классификация по
принципу работы, по охвату
информационных ресурсов, по тематике. Дается определение и описание важного
понятия "релевантность".
В втором
разделе приводятся наиболее популярные
глобальные и российские поисковые
системы с классификацией по охвату информационных ресурсов. Ознакомиться с
современным состоянием этих поисковых систем и узнать их информационные ресурсы
можно в Приложении A
(глобальные поисковые системы) и
в Приложении В (поисковые
системы).
Третий
раздел посвящен языкам запросов, которые позволяют сделать поиск более
эффективным. Отдельно рассмотрены запросы, обрабатываемые
всем поисковыми машинами одинаково, и особенности записи запросов для
вышеописанных поисковых систем.
Локальный поиск на выбранном Web–узле, который очень актуален для информационно насыщенных серверов (издательские дома, библиотеки, крупные научные и учебные заведения и т.п.) описан в четвертом разделе.
В завершении приведены тестовые задания, которые позволят проверить полученные теоретические знания.
1. Принцип работы поисковых систем
Сегодня пользователь World Wide Web оказывается в той же ситуации, что и читатель крупной библиотеки. Чем больше фонды библиотеки, тем труднее найти именно ту книгу, которая сейчас нужна. Для упрощения поиска в библиотеке существуют каталоги: систематический, алфавитный, предметный и другие. Существуют и специализированные каталоги, например каталоги новых поступлений.
Найти информацию помогают поисковые системы Интернета, которые хранят данные о ресурсах Интернета и размещаются на поисковых серверах. Большинство поисковых систем Интернета представлены Web-сайтами, которые обеспечивают интерфейс пользователя с поисковой системой. За время существования Интернета предпринимались различные попытки организации поисковых средств. Многие из этих попыток оказались неудачными, другие же привели к созданию удобных средств поиска информации. Мы рассмотрим поиск информации во Всемирной паутине с помощью нескольких наиболее распространённых систем поиска. Всего же в мире существуют сотни различных поисковых систем, и выбор той или иной системы зависит только от ваших личных пристрастий.
Многие поисковые серверы (далее системы) позволяют искать информацию не только в Web-страницах, но и в группах новостей и хранилищах файлов. Таким образом, в результате поиска вы можете найти сообщение в группе новостей или какой-то файл. Поэтому чаще применяют вместо термина страница общий термин – документ. Под документом подразумеваются Web-страница, сообщение или файл, содержащий различную информацию.
Не смотря на то, что в Интернете размещено порядка 800 млрд. документов, о большинстве из них знают только их создатели. Все дело в том, что специальные средства поиска информации – поисковые системы, могут вывести около 1 млрд. документов. Все остальные остаются вне поля их зрения. Почему так происходит, и как оптимальным путем вести поиск в Интернете – об этом и пойдет речь.
Для поиска информации в сети используются специальные поисковые службы. Обычно поисковая служба — это компания, имеющая свой сервер, на котором работает некая поисковая система. Наиболее известные и популярные системы для поиска информации:
·
Апорт
– http://www.aport.ru/
·
Яndex – http://www.yandex.ru/
·
Rambler – http://www.rambler.ru/
·
Google – http://www.google.ru/,
http://www.google.com/
·
Yahoo! – http://yahoo.com/
·
AltaVista – http://www.altavista.com/
·
Go/InfoSeek – http://www.infoseek.com/
Кроме рассмотренных, существуют также системы для поиска файлов (files.ru), людей (whowhere.ru) и т.
д. Список ссылок на различные поисковые системы размещен на Web-странице
monk.newmail.ru.
Услуги абсолютного большинства поисковых служб бесплатны, но, тем не менее, по темпам роста сегодня это самый эффективный бизнес в мире. Всего за несколько лет такие службы как Yahoo!, AltaVista и некоторые другие развились от лабораторных проектов с бюджетом в десяток-другой тысяч долларов до компаний, стоимость которых составляет 10-15 миллиардов долларов.
Обычно поисковая система представляет собой комплекс из нескольких компьютеров, каждый из которых выполняет свою часть работы. Например, поисковая система Апорт работает на 12 компьютерах под управлением операционной системы Windows NT, Яndex — на шести, а Rambler — на трех Unix-серверах.
Поисковые
системы классифицируются [ 1 ]
I.
По
принципу работы
1.
Поисковые
машины (search engines).
2.
Поисковые
каталоги (directories).
3.
Метапоисковые
машины.
4.
Порталы.
5.
Рейтинговые
службы.
II.
По охвату информационных ресурсов
1.
Глобальные
— всемирный охват материала, хотя упор делается на североамериканские
ресурсы.
2.
Локальные
(региональные) — обеспечивают поиск
по ограниченному сегменту Интернета: российский Интернет, ресурсы
конкретного региона, области, города и т.п.
III.
По тематике
1.
Универсальные
— ищут информацию по любой теме (могут быть как локальными, так и
глобальными).
2.
Специализированные
— ищут информацию по определенному профилю или тематике (преимущественно
локальные).
Умение
пользоваться ими, собственно
говоря, и составляет умение пользоваться Интернетом.
1.1. Поисковые машины
Принцип действия поисковой машины похож на
принцип действия предметного
каталога библиотеки. Пользователь формирует запрос с помощью ключевых слов,
выражающих объект его поиска, а поисковая система выдает ему список ссылок на
Web-страницы,
содержащие данные ключевые слова. Если необходимо найти информацию, посвященную
взаимоотношениям А. Пушкина с Дантесом, можно задать поиск документов, в
которых одновременно встречаются слова Пушкин и Дантес, например: + Пушкин +
Дантес или так: Пушкин AND
Дантес.
Несмотря на то, что результат всегда един (клиент
получает список рекомендованных гиперссылок), принцип действия у
разных поисковых служб может быть различным.
Поисковые машины состоят из следующих основных частей:
1.
Робот
(Robot) или веб-паук (web–spider), червяк, краулер. Многообразие
названий связано с тем, что каждая поисковая система создает свою собственную,
неповторимую программу и дает ей свое имя, которое впоследствии становится
нарицательным. Это программа, которая посещает Web-страницы,
считывает (индексирует) полностью или частично их содержимое и далее следует по
ссылкам, найденным на данной странице. Робот автоматически возвращается через
определенные периоды времени и индексирует страницу снова. Большинство современных поисковых систем начинались с того,
что в 1993-94 годах в университетских лабораториях были разработаны
экспериментальные программы для мониторинга сети.
2.
Индексы.
Все, что находит и считывает Робот, анализируется, и подготавливается
своеобразная выжимка из информации страницы (в том числе и ее URL),
которая включается в индексы поисковой машины. Индексы системы представляют
собой гигантское вместилище информации, где хранится преобразованная особым
образом текстовая составляющая всех посещенных и проиндексированных Роботом
страниц.
На основе этой базы данных поисковая
машина
выдает
ответы на запросы пользователей.
Роботы, как правило, работают постоянно,
накапливая информацию о расположении файлов в Интернете, однако для
пользователей она становится доступной только через некоторое время. Полная и
единовременная смена индексов необходима для корректной работы механизмов поиска
и ранжирования документов. Анализ содержания Интернета — процесс непростой, и
обеспечить непрерывную обработку его результатов бывает сложно.
Все поисковые системы, предназначенные для
сети Интернет, имеют более или менее схожие принципы работы. У каждой поисковой
машины свои приемы и методы индексации. В частности, перед индексацией
большинство машин очищают документ от зарезервированных слов (стоп-слова, stop-words), к которым относятся артикли, предлоги, союзы,
местоимения и другие слова, имеющие менее 4 символов. Однако не только короткие
слова могут быть зарезервированными. Очень распространенные слова, такие как
Computer и
Internet тоже
резервируются. Искать что-то по ним бесполезно, так как они встречаются
повсеместно. Специализированные поисковые службы могут использовать и другие
слова в качестве зарезервированных. Например, если
служба занимается поиском книг (books), то слово
book для нее может
считаться зарезервированным.
На этапе
подготовки к индексации может происходить нормализация слов (stemming) за счет
отбрасывания суффиксов и окончаний. Для каждого слова формируется список всех
его словоформ, и поиск будет производиться по всем словоформам, полученным из
запроса.
Некоторые машины
производят нормализацию всегда. Ряд систем могут действовать и тем и другим
образом. Служба AltaVista не производит нормализацию никогда, и это ее уникальная
особенность, которая активно используется для контекстного
поиска.
На основе "зачищенного" документа готовится
индекс. Существует множество
методов индексации. Разумеется, они не разглашаются. Как и поисковый робот,
алгоритм индексации составляет коммерческую тайну поисковой службы. Примером
простейшего типа индекса является так называемый обратный файл. Суть обратного
файла состоит в том, что составляется словарь из всех слов, встреченных во всех
документах, собранных поисковым роботом, а затем для каждого слова записывается
группа чисел, указывающих на то, в каких документах оно встречается, насколько
часто, а также кое-какая служебная информация.
3.
Поисковая
программа
(алгоритм поиска и оценки результатов). В соответствии с запросом пользователя
эта программа перебирает индексы поисковой машины в поисках информации,
интересующей пользователя, и выдает ему найденные документы в порядке убывания
релевантности.
Накопленная роботом информация перегружается в
генератор выдачи в определенные моменты времени. Период обновления индексов у
трех основных русскоязычных поисковых
машин
— Яndex, Rambler и Апорт — неделя. При этом Яndex и Rambler обновляют общедоступный индекс в выходные, а
Апорт — в рабочие дни.
В идеале за время, которое проходит от одной
смены индекса до другой, поисковая
машина
должна
заново просмотреть и проанализировать все накопленные в ней URL. Но так бывает
не всегда, и тогда в результатах выдачи поисковой
машина появляются устаревшие или
неправильные ссылки, когда по указанному в индексе URL
уже нет зарегистрированной информации.
Поисковая
машина
Яndex справляется с анализом накопленных URL не более
чем за две недели. Для этого используется механизм динамического изменения
периодичности пересмотра URL. То есть если документ не менялся достаточно давно,
то и его содержание можно проверять реже. Но как только машина заметила, что
документ изменен, она будет анализировать его чаще, чем раньше. Таким образом,
Яndex экономит время на анализе мало меняющихся
документов.
Есть, конечно, ресурсы, которые обновляются
каждый день, например интернет-газеты или ленты новостей информационных
агентств. Использовать для поиска по ним существующие
поисковые
машина
нельзя — информация в принципе обновляется быстрее, чем индексируется. Поиск по
таким серверам должен выполняться отдельно, поскольку работа с ними отличается
от поиска в Инернете вообще, и должна быть согласована с авторами ресурсов. Для
этого можно использовать такие системы, как Яндекс.Новости (news.yandex.ru) – поиск по новостным лентам ведущих
информационных агентств, в том числе в определенном временном интервале и в
заданной рубрике. (Главные новости: Политика, В мире, Общество, Экономика, Спорт, Происшествия,
Культура, Наука, Здоровье, Hi-Tech, Интернет, Авто, Туризм, Новости в блогах;
Новости Владивостока; Новости регионов, База данных
СМИ)
В настоящее время все поисковые
машина
предоставляют и различные дополнительные услуги. Например, все они
позволяют
выполнять так называемый нечеткий поиск, при котором сама машина определяет
характерные для документа слова, генерирует запрос, а затем ищет по нему
документы с аналогичными характерными словами. Существует ещё один способ
пополнения информации в базы данных поисковых серверов. В значительной степени, доступность документа
для поисковой машины зависит от его автора. Автор может заметно помочь поисковой
системе, выбрав умело заголовок и подзаголовок,
профессионально пользуясь терминологией и перечислив ключевые слова в
подзаголовках [2]. Разработчик Web-страницы самостоятельно добавляет ссылку на
неё в поисковую систему. Большинство систем позволяют это сделать совершенно
бесплатно.
Так как каждая поисковая машина имеет своего
собственного робота со своими собственными алгоритмами работы с информацией,
индексирует страницы своим особым способом, причем приоритеты при поиске по
индексам тоже отличны, то, произведя запрос по определенным, одним и тем же
ключевым словам или выражениям, мы будем иметь разные результаты для каждой из
поисковых систем.
Многие поисковые машины позволяют проводить поиск в найденных документах, причем вы можете уточнить ваш запрос введением дополнительных терминов. Если интеллектуальность системы высока, вам могут предложить услугу поиска похожих документов. Для этого вы выбираете более подходящий документ и указываете его системе в качестве образца для подражания. Некоторые поисковые машины позволяют провести пересортировку результатов. Для экономии вашего времени можно сохранить результаты поиска в виде файла на локальном диске для последующего изучения в автономном режиме.
Поскольку поисковые системы
существуют в Интернете, в основном, за
счёт публикуемой рекламы, как правило, самые популярные системы поиска могут
предоставить вам наилучшие возможности. Для рядового пользователя услуги
поисковых серверов, как правило, предоставляются бесплатно. Достаточно лишь
указать адрес поисковой системы в рабочей строке браузера или обратиться к ней
через каталог закладок.
Главной задачей любой поисковой системы является поиск информации, соответствующей информационным потребностям пользователя. Очень важно в результате проведенного поиска ничего не потерять, то есть найти все документы, относящиеся к запросу, и не найти ничего лишнего. Поэтому вводится качественная характеристика процедуры поиска – релевантность.
Релевантность – это соответствие результатов поиска
сформулированному запросу.
Рассмотрим это понятие на примере.
Предположим, вам нужно найти курсовую работу на определенную тему. Вы заходите
на поисковую систему и вводите слово для поиска "курсовая работа". Поисковая
система анализирует свою индексную базу и обнаруживает ссылки на 5 197 535
страниц. Причем это слово присутствует как на страницах сайта "База рефератов",
так и в документах, содержащих рабочие программы различных
дисциплин.
Чаще всего пользователь хочет получить первой
ссылку на базу рефератов, чем на страницы где просто употребляется
словосочетание "курсовая работа". Это и называется – релевантность, то есть
степень соответствия запросу.
В том, как поисковая система определяет
релевантность, заключается ноу-хау различных поисковиков.
Однако общий принцип у них достаточно похож: при исчислении
рейтинга учитывается множество
параметров, за некоторые начисляются положительные баллы, а за некоторые –
наоборот штрафные, и анализ результатов
делается примерно следующим образом:
а)
проверяется,
сколько раз заданное слово (словосочетание) встречается на отобранных страничках
– чем больше, тем лучше, потому что больше вероятность того, что эти страницы
посвящены именно данной тематике;
б)
проверяется расстояние между словами,
если введена целая фраза, то более релевантным будет документ, в котором
встречается указанное словосочетание;
в)
количество
ссылок на данную страницу (индекс цитируемости) – чем больше на данную
страницу ссылаются (ставят гиперссылку) другие страницы, тем больше вероятность
того, что именно эта страница нужна пользователю. В традиционном библиотечном
деле такой подход известен. Например, в США давно издается многотомный ежегодный
"Индекс цитируемости" (Citational Index),
в
котором каталогизируются ссылки разных авторов на первоисточники.
г)
каким
шрифтом набрана на странице искомая фраза - если фраза написана крупным шрифтом
(является заголовком) или выделена жирным – это тоже признак более высокой
релевантности данной страницы;
д)
возраст
сайта – чем дольше существует данный сайт, тем лучше это влияет на
релевантность.
Таким образом, уровень
релевантности – это целый комплекс всевозможных параметров, которые нужно не
только получить и сохранить в поисковой базе, но и правильно
интерпретировать.
Некоторые поисковые системы (в том числе и такая известная, как AltaVista) начали повышать рейтинг тем, кто готов за это платить. Они обосновывают это тем, что для потребителя ценность информации на странице солидной фирмы, готовой нести расход на свою рекламу в сети, все-таки выше, чем ценность страницы никому не известного студента.
1.2. Каталоги
Каталог – поисковая система с классифицированным по
темам списком аннотаций со ссылками на Web-ресурсы.
Такая классификация, как правило, проводится людьми.
Поиск в каталоге очень удобен и проводится посредством последовательного уточнения тем, разделов, подразделов и т.д. Кроме этого, каталоги поддерживают возможность быстрого поиска определенной категории или страницы по ключевым словам с помощью локальной поисковой системы. База данных ссылок (индекс) каталога обычно имеет ограниченный объем, заполняется вручную специалистами, создающими каталог. Некоторые каталоги используют автоматическое обновление индекса.
Результат поиска в каталоге представляется в виде списка, состоящего из краткого описания (аннотации) документов с гипертекстовой ссылкой на первоисточник.
Адреса популярных каталогов:
- Апорт (русскоязычный) – http://www.aport.ru/
- Weblist
(русскоязычный) – http://www.weblist.ru/
- Созвездие
Интернет
(русскоязычный) – http://www.stars.ru/
- Yahoo!
(англоязычный) – http://www.yahoo.com/
Регистрация в каталогах полностью зависит от
людей – модераторов данной
системы. Каталог обычно имеет тематическую разбивку на подкаталоги, те в свою
очередь могут подразделяться на более мелкие поддиректории и т.д. Характерный
представитель, считающийся сегодня крупнейшим поисковым каталогом, Yahoo!
(www.yahoo.com), главная страница которого включает, как возможности поиска по
ключевым словам, так и работу с системой каталогов, первый уровень которых
представлен на странице (рис. 1.1, 1.2).
Так как регистрация производится человеком, а
не программой, то поиск по каталогам дает более релевантные результаты, нежели
поиск по поисковым системам.
Рис.
1.1. Фрагмент окна поисковой системы Yahoo!
Поисковые каталоги похожи на предметные каталоги
общественных библиотек. На начальной странице поискового каталога мы выбираем
тему, которая нас интересует, затем в рамках темы выбираем категорию, потом
подкатегорию, и так далее, пока не получим конкретный список Web-ресурсов,
рекомендованных для просмотра.
Основным недостатком и, в то же время,
достоинством поисковых каталогов
является "человеческий фактор". Данные, которые заносятся в каталог, проходят
"ручную обработку". Для этого на поисковую систему работают редакторы, ежедневно
просматривающие Web-пространство в
поисках наиболее ценных ресурсов по темам, вызывающим общественный интерес.
Кроме собственных редакторов службы используют и информацию, поставляемую
Web-мастерами.
Рис.
1.2. Фрагмент окна поисковой системы Yahoo!
с каталогом
Так, например, теоретически любой владелец
Web-страницы может
самостоятельно заполнить предложенную анкету и направить ее в адрес службы.
Правда, гарантии, что страница будет включена в каталог Yahoo!, это не дает.
Служба Yahoo! предпочитает скрупулезно подходить к формированию своих каталогов.
Тщательность в подборе информации обеспечивает высокую репутацию Yahoo!,
несмотря на то, что совокупный объем ее ресурсов крайне
мал.
Другой подход к
формированию каталога демонстрирует поисковая служба Open
Directory
(dmoz.org) (рис.1.3). В качестве источника для своих ресурсов она
привлекает пользователей WWW, которые на
добровольной основе могут обозревать понравившиеся им Web-страницы,
каталогизировать их и размещать ссылки на них на центральном сервере службы. Но
принцип добровольности не гарантирует качественности работы, поэтому каталоги,
равные Yahoo! по качеству, по-видимому, появятся еще не скоро.
Рис.
1.3. Окно диалога поисковой службы Open Directory
(dmoz.org)
1.3. Метапоисковые машины
К метапоисковым машинам относится
множество поисковых служб второго эшелона. Они принимают от пользователя запрос
и размещают его сразу на нескольких поисковых серверах. Потом они собирают
поступившую от них информацию, обобщают ее, структурируют, очищают и передают
клиенту. Увеличенное время исполнения запроса компенсируется улучшенным
качеством результатов поиска. Первое время крупные поисковые системы спокойно
смотрели на существование "под собой" метапоисковых систем. Однако в последнее
время крупные поисковые системы начали заниматься им сами, привлекая ресурсы
коллег на взаимовыгодной основе.
Все больше и больше поисковых систем совмещают
в себе поисковые машины и каталог. Соответственно, индексы для самой поисковой
машины формируются роботом, а каталог пополняется модераторами системы.
В стремлении повысить качество работы
поисковых служб есть попытки совместить оба подхода. При этом возможны два
варианта: поисковые каталоги привлекают возможности поисковых машин, переадресуя
им запрос. Например, до последнего времени поисковый каталог Yahoo!
переадресовывал особо сложные запросы поисковой системе AltaVista. Сегодня
Yahoo! привлекает средства другого партнера — Inktomi.
С другой стороны, поисковые машины научились
выполнять автоматическую каталогизацию своих ресурсов и предоставлять к ним
доступ, так как это принято в поисковых каталогах. Пример такого подхода являет
мощная поисковая система Fast
Search.
Порталами
называются мощные информационные
системы, объединяющие не только несколько отдельных сайтов, но и максимально
возможное количество различных сервисов:
·
Поисковая
машина
·
Каталог
страниц Интернета
·
Служба
новостей
·
Система
электронной почты
·
Электронная
энциклопедия
·
Электронный
магазин
·
Доска
объявлений или форум.
·
Бесплатный
хостинга.
·
Размещение
блогов (сетевых журналов).
В мире существует множество порталов. Хорошие
порталы предоставляют пользователю возможность персональной настройки. Надо
только включить флажки против тех поставщиков информации, которые вам интересны,
и выключить у тех, которые для вас неактуальны.
Многие поисковые системы сегодня превращаются
в порталы. Это означает, что они не только готовы поставлять результаты поиска,
но и способны выполнять другие услуги. Часто название порталов начинается со
слова Му (Мой/Моя/Мое). Например, если на поисковых
системах Yahoo! или AltaVista, вам предлагают подписаться на службу МуYahoo или Му AltaVista, то, значит, речь идет о том,
чтобы стать постоянным клиентом удобного портала.
Другой причиной того, что поисковые машины
постепенно превращаются в порталы, стал тот факт, что им стало трудно
одновременно просматривать пространство WWW, индексировать
гигантские базы данных, и обслуживать запросы клиентов. Поисковые машины
начинают распределять обязанности. Задачи по контролю за Web-пространством
постепенно передаются на партнерских основаниях "третьим" фирмам, а сами
поисковые системы сосредоточиваются на обслуживании клиентов и привлечении
рекламодателей, то есть превращаются в порталы.
Совсем недавно появился новый тип служб,
позволяющих быстро разыскивать информацию в сети, — это так называемые
рейтинговые службы. Они занимают промежуточное положение между поисковыми
машинами и порталами и могут использоваться как в том, так и в другом
качестве.
Суть рейтинговой службы состоит в том, что на
ее сервере создаются тематические списки ссылок на
наиболее популярные Web-ресурсы. Хоть эти списки и небольшие, представительность
их велика, поскольку именно эти ссылки предпочитают большинство клиентов
сети.
Когда мы выбираем одну из ссылок,
представленных на сервере службы, срабатывает счетчик, и рейтинг этого ресурса
увеличивается. Каждый следующий посетитель видит, сколько "нащелкали" его
предшественники, и понимает, какой ресурс ему стоит посмотреть. Поиск с помощью
рейтинговых служб можно рассматривать как поиск "по рекомендациям". Разумеется, он не может претендовать на объективность, но когда речь
идет о темах, имеющих общественный интерес, таких как новости, политика, спорт,
кино, музыка, компьютерные игры и т. п., этим "рекомендациям" можно
доверять. Самая популярная отечественная рейтинговая служба — Rambler
(www.rambler.ru). Наиболее популярная зарубежная рейтинговая служба —
Webside
Story (www.hitbox.com).
2.
Основные
поисковые системы
Ниже перечислены наиболее популярные поисковые
системы с классификацией по охвату информационных ресурсов. Ознакомиться с этими
порталами и узнать их информационные ресурсы можно в Приложении A
(глобальные поисковые системы) и
в Приложении В (российские поисковые
системы).
2.1.
Глобальные поисковые системы
AltaVista (http://www.altavista.com/)
История создания AltaVista начинается с 1995
года, когда в исследовательских лабораториях компании DEC был начат проект,
который и привёл к созданию AltaVista. Web-сервер AltaVista был доступен для
всех желающих. По количеству индексированных Web-страниц AltaVista — одна из
крупнейших поисковых систем мира. Огромный объем охвата Web-пространства и мощный набор поисковых команд делают эту
систему излюбленным средством поиска для большинства пользователей. Система была
запущена в эксплуатацию в декабре
Ask Jeeves (http://www.ask.com/)
Результаты поиска в этой системе используются
и при размещении запроса в AltaVista. Ask.com является одной из старейших
поисковых систем в сети Интернет. Она была создана ещё в 1997 году и тогда
носила имя Ask Jeeves. В то время она функционировала по принципу вопрос-ответ.
В 2001 году Ask Jeeves стала использовать привычный алгоритм с применением
ключевых слов. Однако позже разработчики этого поисковика решили выпустить его
усовершенствованную версию, в связи с чем было
несколько сокращено и его название. Ask Jeeves была преобразована в Ask.com.
На сегодняшний день эта
поисковая система занимает в США четвертое по посещаемости место, однако
разработчики полагают, что в будущем поисковая система сможет улучшить свои
позиции. При этом специалисты делают ставку на высокое качество оказываемых
услуг. Поисковик Ask.com
и портал Lycos,
оба довольно популярные в Соединенных Штатах, объявили о подписании договора, в
рамках которого Ask.com обеспечит поисковые возможности, а также будет
показывать на страницах портала контекстную рекламу.
Excite (http://www.exclte.com/)
Excite — одна из самых
популярных поисковых систем World
Wide
Web. Она имеет
указатель среднего размера и кроме поиска Web-страниц
предоставляет услуги по поиску других материалов, например сведений о компаниях
или результатов спортивных соревнований. Система была создана в конце
FAST Search (http://www.alltheweb.com/)
Эта система, принадлежащая норвежской
компании, ранее называлась AllTheWeb. Она была запущена
в мае 1999 г, а летом 1999 г. FAST
Search
впервые перешагнула
200-миллионный рубеж проиндексированных Web-документов. Кроме
системы FAST
Search та же компания
контролирует подразделение системы Lycos, занимающееся
поиском музыкальных файлов в формате МР3.
Go/Infoseek (http://www.go. com/)
Go/Infoseek — это
сочетание известной в прошлом поисковой системы Infoseek (была
основана в
Google (http://www.google.com/)
Служба Google известна тем, что при генерации
списка ссылок в первую очередь выдает ссылки на те Web-страницы, к
которым из других документов ведет наибольшее количество ссылок. На большинстве
поисковых систем совершенно бесполезно искать информацию по таким тривиальным
словам как Cars (Автомобили),
Internet, WWW , Games
(Игры). Поиск по этим словам
вернет столько ссылок, что среди них невозможно найти самые полезные. Служба
Google при проведении поиска по тривиальным словам дает отличные результаты,
поскольку руководствуется мнением других пользователей, ранее осуществлявших
подобный поиск.
HotBot (http://hotbot.lycos.com/)
По популярности среди сетевой общественности
HotBot приближается к
AltaVista. Как и
AltaVista, эта служба
имеет огромный поисковый указатель и много полезных функций. При генерации
первой страницы ссылок HotBot использует
результаты, поступающие от системы Direct Hit. При генерации последующих страниц
используется система Inktomi, услугами которой пользуются и другие поисковые
службы. Кроме поиска по ключевым словам служба предоставляет также возможность
поиска по тематическому каталогу. Данные для каталога черпаются из проекта
Open
Directory.
Служба HotBot была создана в
мае
Первоначально служба Lycos была запущена
как система, основанная на программе-роботе, собирающей информацию из
WWW. Запущенная в
эксплуатацию еще в мае
Название компании
образовано из латинского словосочетания, которое можно перевести примерно как
волкопаук. В
Yahoo! (http://www.yahoo.com/)
Yahoo! — одна из старейших и наиболее
популярных поисковых служб. Ее каталог был запущен в эксплуатацию еще в
2.2.
Российские поисковые системы
Российский сектор Интернета (Рунет) активно
развивается и способен полностью обслуживать отечественных клиентов. Важную роль
в становлении и развитии Рунета сыграли отечественные поисковые службы. В России
есть как универсальные, так и специализированные поисковые службы.
В российской сети существуют только три
крупных поисковых сервера – Rambler, Яndex и Апорт. Системы проводят автоматическое сканирование
документов расположенных в доменных зонах республик бывшего СССР. При
регистрации страницы, располагающейся в зоне .com, робот проверяет главную
страницу ресурса. При отсутствии русского текста индексация не происходит.
Естественно, что поисковые системы имеют разную степень популярности, которая
выражается в посещаемости соответствующих серверов. Они постоянно развиваются,
предоставляя различные дополнительные бесплатные услуги. Так, наряду с уже
ставшей обычной бесплатной почтой, пользователи могут создать на свою страницу,
легко зарегистрировать Web-ресурсы.
Апорт — один из первых поисковых указателей
российского Интернета — детище компании "Агама" (http://www.agama.ru/). В прошлом служба
предоставляла традиционные общепринятые средства поиска, но в конце 1999 года
внедрила новую систему (Апорт 2000) и интегрировала в себя @Rus — популярнейший
отечественный поисковый каталог, известный в прошлом под именем "Ау!"
(http://www.au.ru/). В результате чего системе Апорт 2000,
которая оставила за собой имя Апорт, удалось мастерски сочетать "машинный" и
"человеческий" факторы. Она использует наиболее эффективную сегодня систему
рейтингования по количеству ссылок, ведущих к данному ресурсу (по индексу
цитирования). По способу представления результатов поиска служба Апорт в
настоящее время является одной из самых передовых не только в России, но и в
мире.
Rambler (http://www.rambler.ru/)
Rambler, запущенная в
1996 году — это в первую очередь
рейтинговая система, обладающая всеми основными функциями поисковых указателей и
одним из крупнейших индексов в России. Она позволяет быстро выявить круг
Web-узлов,
поставляющих информацию на заданную тему и оценить их популярность по количеству
посещений за последние сутки. В 1997 года заработала рейтинговая система
Rambler's Top100, которая с момента своего существования и по сей день считается
лучшим классификатором российского Интернета. Результаты работы Rambler'а содержат минимальное количество
«мусора», что делает его удобным для пользователя. Поиск в различных кодировках
дает одинаковый результат.
Самая популярная (по исследованию
Яndex — мощная
поисковая служба, основанная на указателе, обладающая как большой и
представительной базой данных по отечественным
Web-ресурсам, так и
изощренной системой индексации. Функционирование службы обеспечивает компания
CompTek
(http://www.comptek.ru/).
Яndex предоставляет
уникальные в своем роде инструменты, сосредоточенные в разделе расширенного
поиска.
В области простого поиска служба Яndex имеет ряд
технологических достижений, прежде всего интеллектуальный механизм
морфологического разбора слов, что особенно важно для русского языка. Для
корпоративных клиентов она бесплатно предоставляет "облегченную" версию
программы Яndex.site, выполняющей
индексацию содержимого Web-узла.
WebAlta (http://www.webalta.ru )
Примером новой поисковой системы может служить
WebAlta – Российская IT-компания. Она основана 25 августа 2005
года участниками форума umaxforum.com, которые зарабатывали на конвертации
трафика (дорвеи, поисковый спам, PPC-системы).
Компания специализируется на разработке
инновационных решений в области поиска информации, интернет-рекламы и
развлечений. Ключевой проект компании – поисковый сервис Webalta.
Список поисковых систем далеко не
исчерпывается приведенными примерами. Наряду с развитием универсальных поисковых
орудий, начинают также создаваться поисковые средства узкой отраслевой
направленности, индексирующие информацию, например, только в области
юриспруденции. Изменения, направленные на совершенствование поисковых средств,
происходят довольно часто. Каждая вновь появившаяся система, как правило, в
чем-то превосходит предыдущие, учитывая как позитивный,
так и негативный опыт предшественников. Нет сомнений, что в перспективе
поисковые системы Интернет будут наращивать как аппаратно-программую мощность,
позволяющую им оперативно обследовать самые отдаленные уголки киберпространства,
так и свои искусственно-интеллектуальные способности, обеспечивающие более
точный и взвешенный результат поиска. Все это само по себе повысит удобство
работы в глобальных сетях.
Под языком запроса будем понимать морфологию и синтаксис всех сведений, которые пользователь сообщает поисковой системе прежде, чем начнется процесс поиска.
С морфологической точки зрения данные, содержащиеся в запросе, можно разделить на следующие группы:
- критерии отбора
страниц;
- технология выполнения
поиска;
- параметры формы представления
результатов.
Поисковые системы физически не могут создавать индексы на всех языках. Все поисковые системы имеют "национальную" составляющую. Какие-то из поисковых систем ищут тексты только на английском языке (Yahoo.com, AltaVista.com), какие-то на русском и английском (Rambler), некоторые индексируют страницы на нескольких языках. Например, поисковая система Яndex способна индексировать файлы на русском, английском, немецком, французском, украинском и белорусском языках. Особняком среди этих поисковых систем стоит Google: базовый ее сервер (www.google.com) индексирует файлы на английском языке, а национальные серверы (www.google.de, www.google.fr, www.google.ru) – на своих национальных языках. Все индексные базы находятся в одной глобальной сети, поэтому, можно сказать, что Google – одна из немногих поисковых систем, которая ищет сразу на всех языках в сети.
3.1.
Правила составления запросов к поисковым машинам
При составлении запроса к поисковой системе нужно учитывать следующие положения:
·
необходимо по максимуму указать
слова, которые должны присутствовать в ответе на Ваш запрос. Однако, если указанная комбинация слов отсутствует в индексе
поисковой системы, то необходимо расширить запрос, убрав из него сомнительные
или не обязательные для Вас слова. Необходимо знать, что при этом может в
несколько раз увеличиться количество выдаваемой на запрос информации;
·
некоторые слова в языке (предлоги,
союзы, междометия, частицы, называемые также стоп-словами) не несут семантической нагрузки, а потому
пропускаются поисковой системой;
·
некоторые поисковые системы нормально
обрабатывают синонимы и различные морфологические формы слов. В них, например,
на запрос: "человек ходит", - могут найтись документы, содержащие слова: "люди
идут". Но некоторые поисковые системы не поддерживают синонимов. Так что ответ
на этот вопрос ищите в описании синтаксиса поискового запроса к конкретной
системе. Всегда добавляйте в запросе к омонимам пояснительные слова;
·
многие поисковые системы позволяют
ограничить индексную базу за счет опций: "поиск в найденном", "поиск в
каталоге", "поиск по темам", "поиск картинок", "поиск товаров" и т.п.
3.2.
Запросы, обрабатываемые всем поисковыми машинами одинаково
Самый простой поиск, который вообще может осуществить любой неподготовленный пользователь Интернета – это поиск по ключевым словам. Реализуются они совсем просто:
1.
Нужно открыть браузер Интернета;
2.
Загрузить в него одну из поисковых
систем;
3.
В строке запроса набрать нужные
ключевые слова;
4.
Выбрать в браузере кнопку "Найти"
("Go") или нажать клавишу "Enter".
После выполнения запроса браузер выдаст список страниц сайтов, в котором встречаются данные ключевые слова. Если список не умещается на одной странице браузера, список со ссылками продолжится на других страницах. Переход между страницами прост: в конце каждой страницы с ответом на запрос находятся номера этих страниц. Выбор мышью номера страницы автоматически открывает ее. При этом по ссылкам можно передвигаться как вперед, так и назад.
Однако у этого способа поиска есть недостатки. Вы можете обнаружить нужную информацию на третьей или четвертой странице поиска, а можете вообще не найти среди "сорных" сайтов. Что бы избежать этого надо использовать расширенный поиск, специфичный для каждой поисковой системы, или использовать для поиска ключевые слова. Вначале рассмотрим ключевые слова, которые используются в строке простого поиска.
Для расширенного поиска в Интернет можно использовать регулярные выражения, которые позволяют осуществить поиск по некоторому шаблону слова или выражения. В него включаются как буквы – слова, которые необходимо найти, так и символы, заменяемые другими, произвольными символами.
В регулярных выражениях используются следующие символы:
·
? – символ, указывающий на то, что,
на месте этого знака может встречаться любая буква или цифра, и при том только
одна. Например, выражению м?л удовлетворяют слова
"мал", "мол" и "мел".
·
* – символ,
указывающий на то, что на его месте могут встречаться произвольное число любых
символов, в том числе пустое множество символов (то есть вообще ничего).
Например, выражение "М*" означает любое слово, начинающееся с прописной русской
буквы "М".
Эти символы можно комбинировать. Например, по шаблону: "(?*)" будут искаться все непустые выражения, заключенные в обычные (круглые) скобки.
Другие метасимволы встречаются редко. Здесь просто кратко назовем их: "[", "]", "{", "}", "^". Отметим, что метасимволы "заменяют" символы, поэтому не могут искать сами себя.
Использование метасимволов позволяет во много раз "сократить сущности" при поиске ключевых слов. Например, набрав запрос:
нов??
автомобил*
Вы получите ответ, содержащий слова "новый", "новые", "автомобиль", "автомобили" и т.д. Этот запрос обрабатывается гораздо быстрее и точнее, чем простое перечисление слов.
При комбинации запросов, содержащие несколько слов, может возникнуть ситуация, когда требуется найти не просто ключевые слова, а, например:
·
чтобы все ключевые слова
присутствовали в тексте найденных страниц;
·
чтобы в тексте найденных страниц
присутствовало хотя бы одно слово (этот режим используется при поиске
первоначально);
·
чтобы в тексте найденных страниц
обязательно присутствовали одни слова, и не встречались другие.
Для написания таких запросов нужно использовать выражения булевой алгебры: "И", "ИЛИ", "НЕ". Они обозначаются соответственно как "&", "|" и "~". Запросу <выражение 1> & <выражение 2> удовлетворяет обязательное одновременное присутствие в ответе обоих выражений. Запросу <выражение 1> | <выражение 2> удовлетворяет присутствие хотя бы одного выражения в ответе. И, наконец, запрос <выражение 1>~<выражение 2> выполняется только в случае присутствие первого выражения и отсутствия в ответе второго выражения. Запросы можно объединять, используя круглые скобки, например:
(стар?? | антикварн??) &
автомобил*
Найдет страницы, в тексте которого встречаются слова "старый", "антикварный", "автомобиль" во всех формах.
Запросы, использующие расстояние между словами
Многие поисковые системы позволяют при поиске учитывать расстояние между словами. Условно "расстояние" между словами – это количество посторонних слов, встречающимися вместе со словами, по которым ведется полнотекстовый поиск. Приведем пример. Если задан запрос на поиск в виде следующей фразы:
"широкий стол".
Тогда расстоянием между этими словами в тексте для разных фраз будет:
·
"широкий стол" – два слова;
·
"широкий письменный стол" – три
слова;
·
"Широкий простор открывался из окна.
Поручик сел за обеденный стол." – восемь слов (без
учета стоп-слов "за" и "из", а также знаков препинания).
Естественно, если Вы ищите специально для себя стол, то последний фрагмент Вас не заинтересует. Для поиска устойчивых словосочетаний выбирайте опцию поиска "слова вместе" расширенного поиска, или используйте ключевые слова на ограничение расстояния
В некоторых поисковых машинах предусмотрена опция "поиск по странам" и "поиск по регионам". Для этого пользователь в специальном поле формы запроса пишет (или выбирает) название страны и региона. В этом случае ответы на запрос "фильтруются" по Интернет-адресам серверов, расположенных в данном регионе.
Поиск по типам файлов (фильтр)
Некоторые поисковые системы предоставляют услугу фильтрации содержимого по типу файлов. Так, по умолчанию поиск ведется только по Web-страницам (html-файлам). При включении этого фильтра также будет осуществляться поиск в файлах формата Adobe Acrobat (.pdf), Microsoft Word (.doc), Microsoft Excel (.xls), Microsoft PowerPoint (.ppt) и Macromedia Flash (.swf). Необходимо только учесть, что проиндексированного содержимого этих файлов гораздо меньше, чем HTML, поэтому, если поиск с использованием этого фильтра даст отрицательный результат, это не значит, что таких фрагментов в этих файлах нет – скорее всего, их просто нет в индексе.
Поиск по дате модификации файла
Встроенный фильтр некоторых поисковых систем позволяет проверять и выбраковывать Web-страницы, закаченные на Web-сервер раньше или позже определенных дат. Этим фильтром можно отсечь "мертвые", давно не обновляющиеся страницы.
Этот фильтр позволяет отсечь слишком малые (меньше 1 Кб) или слишком большие файлы или Web-страницы. Этот фильтр применим только к файлам, но не к каталогам.
По умолчанию поисковая система ищет только оригинальные страницы, а не их копии на других Web-сайтах (так называемых "зеркалах", "mirror" по-английски). Чтобы система не игнорировала зеркала, необходимо включить эту опцию.
Обработка регистров букв в запросе
В общем случае регистр написания букв в поисковых словах и операторах значения не имеет. То есть такие слова, как конь и КОНЬ, and и aND воспринимаются поисковыми системами как одинаковые. Однако, в некоторых поисковых системах, с целью повышения качества поиска, регистр слов в запросе принимается во внимание. Прежде всего, это касается обработки имен собственных.
Для поиска цитат можно использовать двойные кавычки. Слова запроса, заключенного в двойные кавычки, ищутся в документах в тех форматах и в том порядке, в котором они встретились в запросе.
Следовательно, двойные кавычки можно использовать и просто для нахождения слова в заданной форме (по умолчанию слова находятся во всех морфологических формах).
По каждому слову запроса ведется поиск с учетом правил словообразования и морфологии соответствующего языка. Например, при поиске по слову "человек" будут найдены документы, содержащие слова "человеку", "человеком", "человека", и даже "люди". Чтобы произвести поиск только по одной определенной форме слова, нужно взять его в двойные кавычки, или воспользоваться поиском точной фразы в расширенном поиске.
Некоторые поисковые системы понимают и различают слова русского и английского языков.
Некоторые слова и символы по умолчанию исключаются из запроса в связи с их малой информативностью. Это так называемые стоп-слова самые частотные слова русского и английского языка: предлоги, частицы, союзы и артикли. Присутствие этих слов может замедлить поиск и негативно повлиять на полноту результатов. Если необходимо все-таки включить эти слова в поиск, используйте двойные кавычки.
3.3.
Язык запроса глобальных поисковых систем
AltaVista (http://www.altavista.com)
AltaVista позволяет осуществлять простой и расширенный поиск, а также предоставляет дополнительные сервисы, облегчающие навигацию в среде WWW. Все страницы пользовательского интерфейса снабжены ссылкой на специальный раздел "Help" (помощь), который позволяет даже неподготовленным пользователям правильно составлять простые и сложные запросы.
Помимо собственной базы система предоставляет пользователям доступ к следующим информационным массивам:
·
Suggested Relevant Searches;
·
База данных
RealNames;
·
Поисковая
система AskJeeves;
·
каталог
Интернет-ресурсов Open
Directory (при
поддержке LookSmart);
·
база
данных, содержащая информацию о группах новостей (версия БД RemarQ);
·
специализированные
базы данных, содержащие сведения о мультимедийной информации.
Основными достоинствами поисковой системы являются: значительный объем базы; широкие возможности для составления поискового выражения как с использованием логических операторов, так и с использованием шаблонов; хорошо разработанные алгоритмы индексирования документов; возможность настройки пользовательского интерфейса и создания предустановок поиска.
Недостатками системы, по мнению экспертов, являются ограниченные возможности сортировки результатов поиска и недостаточно четкая обработка запросов, введенных строчными и прописными буквами.
Простой поиск
Запрос из ключевых слов вводится в
поисковое поле "Find"
(рис. 3.1). Выше поля ввода
расположены несколько ярлычков, щелчком на которых можно выбрать область поиска:
Web (Паутина) – во Всемирной паутине, News (Новости) – в группах новостей и так
далее.
Для поиска документов
содержащих некоторое слово, надо ввести это слово, а для поиска документов,
содержащих искомое словосочетание, необходимо заключить несколько слов в двойные
кавычки. Если слово содержит только строчные буквы, то ему сопоставляются также
и слова, содержащие заглавные буквы.
В системе «AltaVista»
можно задавать только часть слова, используя для этого метасимвол «*», который
заменяет от 0 до 5 букв. Использование этого знака похоже на его использование в
шаблонах файлов.
Внизу справа находится меню для ограничения поиска документами на английском или другом языке.
Рис. 3.1. Поисковое окно для ввода
запроса поисковой системы AltaVista
По умолчанию используется логический оператор OR, однако ввод самих логических операторов в простом поиске не поддерживается. AltaVista позволяет при помощи знаков " + " и " - " искать документы как содержащие, так и не содержащие заданные слова. Различаются запросы, введенные строчными и прописными буквами.
AltaVista поддерживает поиск по фразе, которая заключается в кавычки. Помимо кавычек система учитывает следующие знаки препинания, служащие для связи слов: %, $, /, #, _ . При поиске слова, связанные этими знаками, воспринимаются как фраза.
Поддерживается функция усечения справа, при этом ключевое слово вводится со знаком "*", поставленного после слова без пробела.
AltaVista поддерживает поиск не только в текстовой части html‑документа, но и в других его разделах. Для этого используются следующие специальные операторы:
·
Anchor
– документы,
которые содержат ключевое слово в тексте гиперссылки;
·
Applet
– документы,
содержащие Java applet;
·
Domain
– документы
только внутри обозначенного домена. Например: только внутри домена
.org;
·
Host
– документы
на определенном узле (компьютере). Например: только на сервере
www.nlr.ru;
·
Image
– документы,
содержащие рисунки, обозначенные заданным ключевым словом;
·
Link
– документы,
содержащие ссылки на определенный
URL;
·
Text
– документы,
содержащие ключевое слово в любой части документа;
·
Title
– документы,
содержащие заданное слово в заголовке (появляется в строке заголовка браузера);
·
Url
– документы,
содержащие заданные слова в URL.
При работе с поисковой системой пользователь имеет возможность формулировать свой запрос на естественном языке. Запрос можно вводить только в поисковое окно "Search for" (рис. 3.1) на странице простого поиска.
Отличительной особенностью AltaVista является наличие двух расширенных поисковых интерфейсов "Advanced Search" (вызывается активизацией ссылки "Advanced Search") и "Power Search" (вызывается активизацией ссылки "Settings").
Расширенный поиск (Advanced Search )
AltaVista поддерживает использование следующих операторов: OR, AND, AND NOT, NEAR. Система позволяет комбинировать запрос из двух частей. В одно поисковое поле вводятся слова, связанные логическими операторами, в другое уточняющие ключевые слова (рис. 3.2) . Это значит, что первыми в итоговом списке документов, строго соответствующих запросу с логическими операторами, будут проранжированы документы, содержащие уточняющие ключевые слова (ранжирование по степени соответствия запросу).
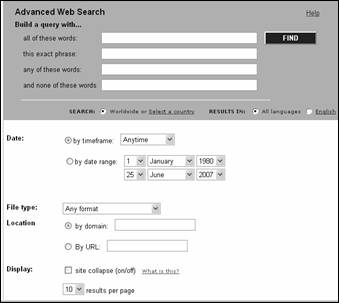
Рис. 3.2. Форма для ввода запроса расширенного поиска AltaVista
Ниже располагаются области уточнения запроса по языку, на котором написан документ ("Results in"). Существует возможность ограничения поиска по дате создания (или последнего индексирования) поисковой программой ("Date"). Можно задать поиск документов за предлагаемые периоды времени ("Anytime", "Today", "Week", "2 Weeks", "Month", "3 Months", "6 Months", "Year"), либо ввести точные даты в поля опции "by date range".
Возможно задание поиска по типу файла ("File type"), по месту расположения ("Location"). Область уточнения запроса "Location" дает возможность ограничить, страной или конкретным узлом. Регион выбирается из опций раскрывающегося меню "by domain": Опция "Display" определяет количество ссылок, выводимых на страницу с результатами поиска.
Расширенный поиск (Power Search)
Интерфейс расширенного поиска Power Search поисковой системы AltaVista представляет собой шаблон, состоящий из нескольких областей уточнения запроса (рис. 3.3).
Первая гиперссылка позволяет выйти страницу, которая ограничивает поиск документов заданным географическим регионом страну поиска ("Country"). Опция "by domain" содержит поле для ввода доменов верхнего уровня. Опция "Search only this Web Site" дает возможность проводить поиск документов на конкретном сайте.
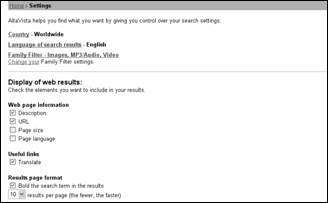
Рис . 3.3. Область уточнения запроса
поисковой системы AltaVista
Вторая гиперссылка "Language of search results" позволяет выбрать интересующий вас язык искомого документа: щелкните гиперссылку и в открывшемся окне выбора языка (рис. 3.4) выберите Russian (Русский) или любой другой язык из списка (пользователь выбирает один из 25 языков или "any language", т.е. поиск без ограничения). По умолчанию ищется информация на любом языке.
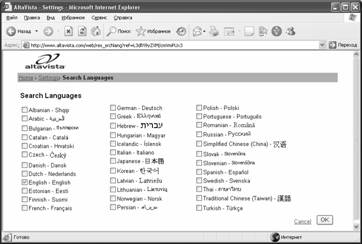
Рис.3.4. Окно
выбора языка поиска системы AltaVista
Пользователь может настроить формат выдачи результатов, который состоит из следующих элементов (раздел "Web page information"):
·
Description
– первая
строка найденного документа;
·
URL
– URL-адрес
документа;
·
Web Page
Size – размер
документа в килобайтах;
·
Web site language – язык
документа.
Раздел
"Useful links",
содержащий опцию Translate – при
отображении результатов поиска выводит ссылку на встроенный переводчик системы Babel
Fish;
Область уточнения "Results page format" задает параметры выдачи результатов поиска. Так опция "Bold the search term in the results" позволяет визуально выделить ключевые слова в описании или заголовке документа. Опция "Results per page" задает количество ссылок (от 10 до 50), выводимых на страницу результатов.
Созданные предустановки запоминаются браузером и действуют в каждой поисковой сессии, пока не будут изменены.
Результаты поиска и дополнительные возможности
В начале списка результатов поиска помещаются документы, которые содержат все заданные слова, причем преимущество отдается документам, в которых эти слова находятся рядом друг с другом и ближе к началу документа. Каждый результат поиска выдается в виде заголовка документа и краткого описания страницы, которое берется или из поля "META" html-документа, или из первых строк документа. Ниже указывается URL документа (рис. 3.5).
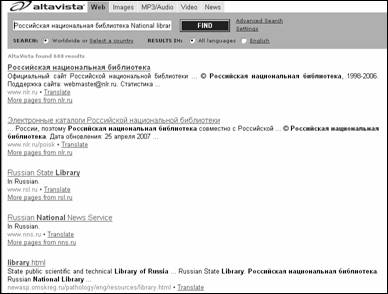
Рис. 3.5.
Формат выдачи результатов поиска поисковой системы
AltaVista
Ссылка "More Pages from this Site" позволяет увидеть другие страницы данного сайта, релевантные запросу, потому что при выдаче результатов поисковой системы AltaVista представляет описание только одной страницы с конкретного сайта. "Related Pages" – ссылка на список документов, найденных по запросу в каталоге Интернет-ресурсов LookSmart.
Опция "Search within these results" позволяет провести повторный уточняющий поиск среди уже найденных документов. С помощью шаблона страницы предустановок поиска.
Система поддерживает поиск документов и файлов, содержащих мультимедийную информацию (изображения, аудио – и видеозаписи). Для этого пользователю предлагаются три специальных поисковых интерфейса Images, MP3/Audio и Video, переход на которые возможен с любой страницы поисковой системы.
Кроме того, AltaVista предлагает пользователям доступ к специализированной базе Education Search, в которой проиндексировано более 20 миллионов Web-страниц высших и средних учебных заведений.
Система имеет встроенный переводчик Babel Fish для перевода
небольших фрагментов произвольно набранного текста или фрагмента документа,
представленного в списке результатов запроса. Ограничение размера – 5 Кб текста
в html-документе.
Помимо поиска по ключевым словам пользователь может проводить поиск в каталоге, который поддерживает поисковая система LookSmart. Это один из крупнейших каталогов Интернет-ресурсов, содержащий более 2.300.000 отобранных ссылок. Он разбит на 17 категорий, каждая из которых делится на более дробные подразделы. Описание документа состоит из заголовка и краткой характеристики.
AllTheWeb (FAST Search) (http://www.alltheweb.com)
В качестве точки доступа к базе FAST Search был выбран интерфейс расширенного поиска поисковой системы Lycos. Параллельно ведутся работы над созданием собственного поискового интерфейса системы. Сейчас он представлен страницами простого и расширенного поиска. Кроме того, пользователи получают доступ к базе FAST Search, содержащей сведения о мультимедийной информации. Поиск в базе данных, индексирующей содержимое файловых архивов, по-прежнему осуществляется с севера Lycos.
Достоинствами поисковой системы являются высокая скорость обработки запроса, отсутствие списка стоп-слов и возможность вывода до 100 ссылок на одну страницу результатов поиска.
Основной недостаток поисковой системы, по мнению экспертов, заключается в ограниченном наборе поисковых функций. Система не поддерживает ввод запроса с использованием логических операторов и операторов близости, а также поиск с усечением ключевых слов. Составление поискового выражения возможно только при помощи шаблонов.
Простой поиск
Интерфейс страницы простого поиска поисковой системы FAST Search представляет собой поле для ввода ключевых слов (рис.3.6).
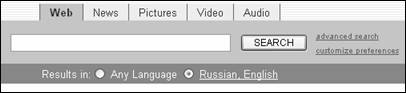
Рис. 3.6. Поле для ввода ключевых
слов поисковой системы FAST Search
Ниже поля запроса отображается переключателю, дающие возможность выбора языка поиска, а вкладки сверху ограничивают тематику: "news" (новости), "pictures" (изображения), "video" (видеофайлы) и "audio" (аудиофайлы). Система поддерживает ввод запроса с использованием специальных операторов "+" и "-", которые соответствуют логическим операторам "AND" и "NOT". Фраза заключается в кавычки. Строчные и прописные буквы при поиске не различаются.
Основными дополнительными возможностями системы являются создание предустановок как для простого, так и для расширенного поиска. Имеется также доступ к базе поисковой системы FAST Search, содержащей сведения о мультимедийной информации.
Справа от поля для ввода ключевых слов располагаются ссылки на страницу создания предустановок поиска ("customize preferences") и на страницу расширенного поиска ("search").
Страница создания предустановок поиска содержит восемь ссылок на страницы настроек (рис. 3. 7):
1.
"Basic Settings"
– изменяя параметры настроек с этой страницы (количество ссылок на листе, шрифт
ссылок и т.п.), пользователь может полностью персонализировать поиск, используя свой опыт.
Например, функция
"Offensive content
filter"
позволяет исключить из результатов поиска документы, содержащие ненормативную
лексику. В полной мере она распространяется только на документы на английском
языке. Функция "Highlight Search Terms" дает
возможность при выдаче результатов поиска выделять цветом ключевые
слова.
2.
"Advanced Settings"
–
здесь
пользователь может использовать больше передовых особенностей (например,
автозавершение поисковой фразы) и параметров настройки типов
поиска.
3.
"Language"
– на
этой странице пользователь может ограничить поиск на страницах с определенными
языками. Для того чтобы AlltheWeb правильно
интерпретировал и показывал результаты поиска на определенном языке,
пользователь может выбирать систему кодировки символов, который соответствует
вашим параметрам настройки браузера. Возможен выбор 8 языков из 36
поддерживаемых поисковой системой.
4.
"Look and Feel" – AlltheWeb позволяет
пользователю написать свой собственный файл CSS
AlltheWeb.com для отображения
внешнего вида окна.
5.
"Keyboard Shortcuts" –
используя эту ссылку пользователь может назначить
клавишам различные действия, чтобы сделать возможным работу с системой почти без
использования мыши.
6.
Save and apply settings"
– ссылка позволяет сохранить и применить предустановки;
7. "Restore defaults" – при щелчке на эту ссылку произойдет восстановление значений параметров предустановки по умолчанию;
8. "Exit" – выход из режима предустановки.
Созданные предустановки запоминаются браузером и действуют в каждой поисковой сессии, пока не будут изменены.
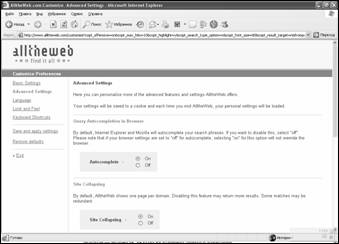
Рис. 3.7. Окно предустановок поисковой системы
alltheweb
Помимо поиска мультимедийной информации поисковая система FAST Search предлагает пользователям такую интересную возможность, как поиск Web-страниц, созданных для мобильных телефонов с поддержкой протокола WAP.
Внизу страницы есть ссылки на справочный раздел по составлению запросов ("help").
Расширенный поиск
Интерфейс расширенного поиска поисковой системы FAST Search представляет собой шаблон, состоящий из словарного фильтра и нескольких областей для уточнения запроса (рис.3.8).
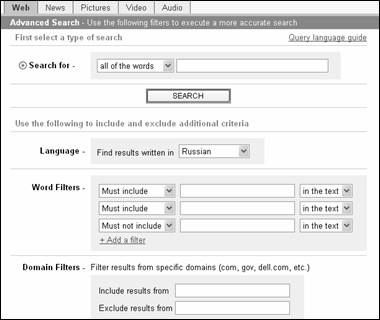
Рис. 3.8.
Интерфейс расширенного поиска поисковой системы Fast
Search
Словарный фильтр "Search for" идентичен фильтру на странице простого поиска. Ниже пользователю предлагаются дополнительные возможности для составления поискового предписания.
·
"Language"
– фильтр ограничения по языку, на котором написан документ. Справа находится
раскрывающееся меню, которое позволяет пользователю указать наиболее
предпочтительную для него кодировку документа.
· "Word
Filters" – дополнительный словарный фильтр. По умолчанию он состоит из трех
одинаковых полей. При необходимости поля можно добавить или убрать,
воспользовавшись кнопкой Filters "+" или "-". Опции
раскрывающихся меню слева имеют обозначения: "Should include" (возможно
содержит), "Must include" (должен содержать) и "Must not include"
(не должен содержать), что соответствует по смыслу логическим операторам OR, AND
и NOT. Опции раскрывающихся меню справа позволяют производить поиск в различных
частях html -документа:
· " Domain
Filters" – фильтр ограничения поиска документов по домену узла, на котором
находится документ.
· "Result
Restrictions" – фильтр, дающий возможность задать количество ссылок на
странице результатов поиска (раскрывающееся меню "Results per page") и
исключить из результатов поиска документы, содержащие ненормативную лексику
("Offensive content reduction").
Результаты поиска и дополнительные возможности
Результаты поиска выдаются в виде заголовка документа, первых строк текста и URL-адреса. На первой странице указывается количество найденных по запросу документов и время, затраченное поисковой системой на проведение поиска (рис. 3.9).
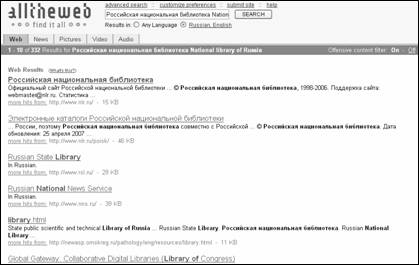
Рис. 3.9.
Формат выдачи результатов поиска поисковой системы FAST
Search
Google (http://www.google.com)
Система предлагает пользователю простой и расширенный поисковый интерфейсы, а также страницу создания предустановок поиска.
Отличительной особенностью поисковой системы Google является технология определения степени релевантности документа путем анализа ссылок других источников на данный ресурс. Эта технология называется PageRankTM. Чем больше ссылок на какую-либо Web‑страницу имеется на других страницах, тем выше ее рейтинг в базе Google. При выдаче результатов поиска в начале списка оказываются страницы с более высоким рейтингом (при прочих равных составляющих).
Помимо основной базы запрос обрабатывается с использованием таких информационных массивов как база данных RealNames и каталог Интернет-ресурсов Google Web Directory.
Google предоставляет доступ к своей базе другим поисковым системам, среди которых наиболее известными являются Netscape's Search и Yahoo!.
Основными достоинствами поисковой системы являются значительный объем базы, маленький список стоп-слов и возможность получения копии документа из базы Google, если он удален с основного адреса.
Недостатками поисковой системы являются отсутствие поддержки логических операторов AND и NOT, невозможность составления поисковых предписаний с использованием скобок, отсутствие поисковой функции усечения.
Простой поиск
При обработке запроса система интерпретирует пробел между словами как логический оператор AND, однако ввод самого оператора не поддерживает. Запрос вводится в поисковое поле (рис.3.10, 3.11). Кнопка "I'm Feeling Lucky" или "Мне повезёт!" прерывает поисковую сессию и открывает в окне браузера первый найденный документ. Справа расположены ссылки на страницу расширенного поиска ("Advanced Search") и страницу задания параметров поиска ("Preferences").
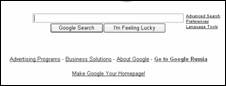
Рис.
3.10.Поле для ввода ключевых слов поисковой системы Google.com
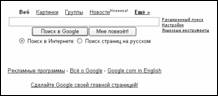
Рис.
3.11.Поле для ввода ключевых слов поисковой системы Google.ru
Если необходимо провести поиск с использованием стоп-слов, то перед ними проставляется знак "+". Система поддерживает использование логического оператора ОR. Оператор NOT заменяется знаком "-" перед словом без пробела. Возможна постановка знаков "+" и "-" перед фразой.
Поддерживается поиск по фразе, которая заключается в кавычки. Помимо кавычек Google учитывает следующие знаки препинания, служащие для связи слов: дефисы (mother-in-law), косые черты (national/library/russia), знаки равенства (national=library=russia), апострофы (Bill's birthday). При поиске слова, связанные этими знаками, воспринимаются как фраза.
Система не поддерживает поиск с учетом морфологии, поиск по части ключевого слова и не различает строчные и прописные буквы.
При составлении поискового выражения можно использовать два специальных оператора. Оператор "link:" дает возможность выявить документы со ссылкой на данный URL. Например, на запрос "link:www.nlr.ru" будут получены документы со ссылками на домашнюю страницу РНБ. Такой запрос нельзя комбинировать с обычными ключевыми словами. Оператор "site:" сужает круг поиска документами с определенного Web-сайта. Например, по запросу "site:www.nlr.ru database" будут найдены документы на Web-сайте РНБ, содержащие слово "database".
Расширенный поиск
Интерфейс страницы расширенного поиска реализован в виде шаблона, состоящего из различных фильтров (рис.3.12, 3.13).
Первый
фильтр для ввода ключевых слов "Find results" ("Найти
результаты"состоит из 4-х
полей:
·
"with
all of the words" ("со всеми словами") – соответствует логическому оператору
AND;
·
"with
the
exact
phrase" ("с
точной фразой") – поиск по фразе;
·
"with
the
least
one
of the
words" ("с любым
из слов") – соответствует логическому оператору OR;
·
"without
the words" ("без слов") – соответствует логическому оператору
NOT.
Справа располагается раскрывающееся меню, позволяющее задать количество ссылок результата поиска, выводимых на одну страницу (от 10 до 100).
Фильтр "Occurrences" ("Упоминание") позволяет производить поиск ключевых слов в определенных областях html-документа: "anywhere in the page" ("где угодно на странице"), "in the title of the page" (в заголовке документа), "in the url of the page" (в URL-адресе документа).
Фильтр "Language" ("Язык") позволяет осуществлять поиск документов на одном из 25 языков, указанных в опциях раскрывающегося меню.
Фильтр "Domains" ("Домен") позволяет как искать документы, находящиеся на определенных узлах, так и исключать их из результатов поиска.
Фильтр "SafeSearch" позволяет исключить из результатов поиска документы, содержащие ненормативную лексику.
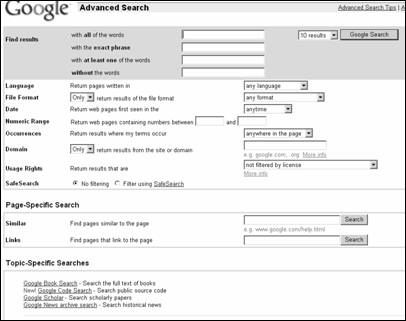
Рис. 3.12. Интерфейс страницы
расширенного поиска поисковой системы Google.com
Следующая область страницы расширенного поиска "Page Specific Search" ("Поиск по странице") содержит два поисковых поля "Similar" ("Похожие") и "Links" ("Ссылки"). Поле "Similar" ("Похожие") служит для поиска документов, наиболее релевантных данному: здесь помимо ключевых слов учитывается домен узла, тип документа и проч. Поле "Links" ("Ссылки") служит для поиска документов, содержащих ссылки на заданную страницу. Раздел "Topic-Specific Searches" позволяет организовывать поиск по определенным темам.
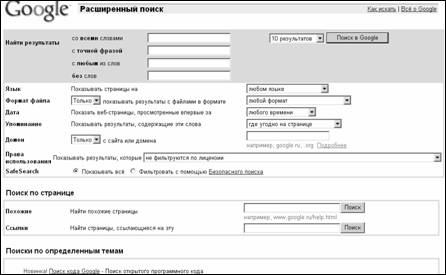
Рис. 3.13. Интерфейс страницы
расширенного поиска поисковой системы Google.ru
Результаты поиска и дополнительные возможности
Как уже было сказано, Google определяет степень релевантности документа путем анализа ссылок других источников на данный ресурс. При сортировке результатов поиска из всех релевантных документов выбираются страницы с более высоким рейтингом и помещаются в начало списка.
Перед списком результатов указывается количество документов, найденных по запросу, и время обработки запроса в базе Google. Формат вывода результатов поиска состоит из следующих элементов (рис. 3.14, 3.15):
·
заголовок
документа;
·
выдержки из
текста с выделенными жирным шрифтом словами запроса;
·
описание
документа, полученное из поля meta ("description");
·
ссылка на
соответствующий раздела каталога Google Web Directory
("category");
·
URL-адрес
страницы;
·
размер
найденного документа в килобайтах;
·
ссылка на
копию документа в базе Google ("cached", "Сохранено в
кэше");
·
ссылка для
задания поиска документов, наиболее релевантных данному
("Similar
pages", "Похожие страницы"); здесь помимо ключевых слов учитывается домен узла,
тип документа и проч.;
·
другие
страницы сайта, релевантные запросу, если таковые имеются ("more results from",
"дополнительные результаты").
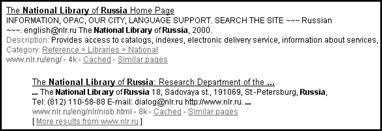
Рис. 3.14.
Формат выдачи результатов поиска поисковой системы Google.com

Рис. 3.15.
Формат выдачи результатов поиска поисковой системы Google.ru
Google предоставляет пользователю разнообразные возможности по настройке интерфейса системы и непосредственно самих поисковых функций. На домашней странице имеется ссылка на страницу создания предустановок поиска "Preferences" или "Настройки" (рис. 3.16, 3.17). Поисковая система поддерживает интерфейсы на 25 языках и позволяет открывать каждый найденный документ в новом окне браузера. Пользователь может задать поиск документов одновременно на нескольких языках, регулировать количество результатов поиска, выводимых на одну страницу, а также подключать фильтр для документов, содержащих ненормативную лексику. Созданные предустановки запоминаются браузером и действуют в каждой поисковой сессии, пока не будут изменены.
На странице расширенного поиска расположены ссылки на специализированные информационные массивы поисковой системы. Это каталог высших учебных заведений, в основном американских и канадских, хотя географический охват постоянно расширяется; база Web-сайтов правительственных и военных учреждений (материалы фильтруются по доменам верхнего уровня .gov и .mil); база Web‑сайтов по программному обеспечению различных операционных систем.
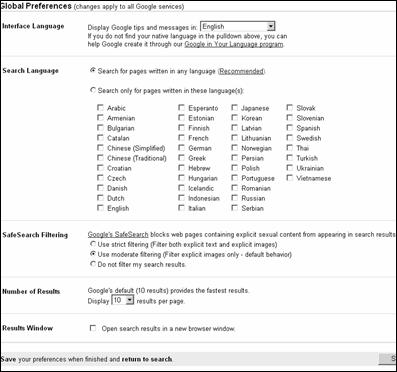
Рис. 3.16. Окно предустановок поиска
поисковой системы Google.com
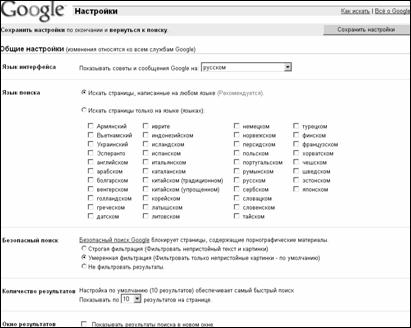
Рис. 3.17. Окно предустановок поиска поисковой системы
Google.ru
Как уже было отмечено выше, при выдаче результатов поиска большинство найденных документов сопровождаются ссылкой "category" или "Каталоги" на соответствующий раздел каталога Google Web Directory. В основе этого каталога лежит каталог Интернет-ресурсов Open Directory Project (http://dmoz.org), созданный компанией Netscape. На данный момент в нем содержится около 1,5 миллионов ссылок. Каталог постоянно пополняется новыми материалами, которые присылают редакторы, работающие на добровольных началах. Подробное описание этого каталога содержится в разделе "Каталоги Интернет-ресурсов".
Иерархическая структура Yahoo! основывается на сокращенной версии списка предметных рубрик Библиотеки Конгресса и насчитывает более 100.000 категорий. Работа над каталогом ведется коллективом опытных редакторов, многие из которых имеют профессиональную библиотечную подготовку. В постоянном штате числятся до 150 редакторов. Помимо этого каталог постоянно пополняется ссылками, которые присылают рядовые пользователи сети Интернет.
Поисковая система имеет простой и расширенный поисковый интерфейсы.
Простой поиск
Простой поиск осуществляется с домашней страницы сайта. Ключевые поля вводятся в поле запроса (рис. 3.18, 3.19).
![]()
Рис. 3.18. Строка для ввода
запроса поисковой системы yahoo.com

Рис. 3.19. Строка для ввода
запроса поисковой системы ru.yahoo.com
Встроенная поисковая система поддерживает ввод запроса с логическими операторами AND ("+") и OR, последний используется по умолчанию. Логический оператор NOT заменяется постановкой знака "-" перед ключевым словом. Возможна постановка знаков "+" и "-" перед фразой, которая заключается в кавычки. Для поиска ключевых слов в заголовке html-документа используется специальный оператор "t:". Поддерживается поисковая функция усечения справа, при этом ключевое слово вводится со знаком "*" для замены любого количества символов.
Расширенный поиск
Переход на страницу расширенного поиска осуществляется с домашней страницы каталога по ссылке "Расширенный" или со страницы с результатами поиска по ссылке "Advanced". Интерфейс расширенного поиска содержит поле для ввода ключевых слов и две области уточнения запроса (рис. 3.20, 3.21). Первый фильтр для ввода ключевых слов "Find results" ("Найти результаты"состоит из 4-х полей:
·
"with
all of the words" ("со всеми словами") – соответствует логическому оператору
AND;
·
"with
the
exact
phrase" ("с
точной фразой") – поиск по фразе;
·
"with
the
least
one
of the
words" ("с любым
из слов") – соответствует логическому оператору OR;
·
"without
the words" ("без слов") – соответствует логическому оператору
NOT.
Область "Select a search area" дает возможность искать документы либо только в каталоге Yahoo!, либо в базе данных Google. Можно ограничить поиск датой добавления документа в каталог (за последний день, за последние 3 дня, за последнюю неделю, месяц, 3 месяца, 6 месяцев или 4 года).
Фильтр "Creative Commons search" ("Фильтр безопасного поиска") позволяет исключить из результатов поиска документы, содержащие ненормативную лексику
Рис. 3.20. Интерфейс
расширенного поиска поисковой системы Yahoo!
При выдаче результатов поиска все документы ранжируются по степени релевантности. При прочих равных условиях выше ранжируются документы, которые содержат ключевые слова в заголовке. Первыми выводятся ссылки на категории и рубрики каталога, содержащие ключевые слова. Затем пользователю предлагается список найденных документов, состоящий из названия, URL-адреса и краткой аннотации. Если поиск в Yahoo! дает отрицательный результат, то запрос автоматически переадресовывается поисковой машине Google, которая осуществляет полнотекстовый поиск документов в масштабе всей сети WWW.
Кроме основной англоязычной версии каталог Yahoo! предлагает пользователям версии сайта, полностью переведенные на другие языки (немецкий, французский, шведский и т.д.). Ссылки на эти версии расположены в нижней части домашней страницы поисковой системы.
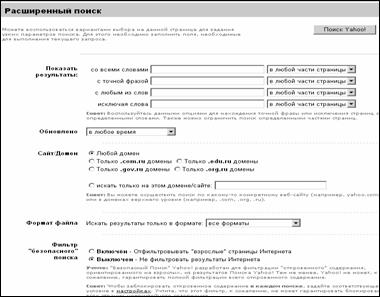
Рис. 3.21. Интерфейс
расширенного поиска поисковой системы Yahoo! по‑русски
3.4. Язык запроса русских поисковых систем
Система обладает широким спектром поисковых возможностей. Она позволяет осуществлять простой и расширенный поиск и является единственной поисковой системой с интегрированным каталогом Интернет-ресурсов. Особые алгоритмы индексирования позволяют программе-роботу при обработке документов учитывать имеющиеся в них ссылки, что существенно расширяет поисковое пространство системы. Апорт обладает функцией встроенного переводчика, это дает пользователю возможность формулировать запросы как на русском, так и на английском языках.
Простой поиск
Запрос из ключевых слов вводится в поисковое поле, расположенное в
верхней части домашней страницы (рис. 3.22). Обычно запрос состоит из одного или
нескольких слов, например:
"микропроцессоры компании Intel".
По умолчанию используется логический оператор "AND". Ниже находятся селекторные кнопки, позволяющие выбрать информационный массив, в котором будет производится поиск.

Рис. 3.22.
Поле для ввода ключевых слов поисковой системы Апорт
Система поддерживает составление запроса с использованием логических операторов И ("AND", "+", "&"), ИЛИ ("OR", "|") и НЕ ("NOT", "‑"). Для составления сложного поискового выражения используются круглые скобки, задающие порядок действия операторов.
Логические операторы
|
|
Синонимы |
Описание |
И |
AND |
Оператор логическое И (подразумевается, его можно опускать): запрос
"быстрый поиск" полностью эквивалентен запросу "быстрый И
поиск". По любому из этих запросов будут найдены документы, содержащие
оба слова. |
|
ИЛИ |
OR |
Оператор логическое ИЛИ позволяет искать документы,
содержащие хотя бы один из операндов. По запросу "быстрый ИЛИ
поиск" будут найдены документы, содержащие любое из указанных слов или
оба слова одновременно. |
|
НЕ |
NOT |
Оператор логическое НЕ
ограничивает поиск документами, не содержащими слово, указанное после
оператора. По запросу "фрукты НЕ яблоки" будут найдены документы,
содержащие слово "фрукты", но не содержащие слово
"яблоки". |
|
() |
|
Круглые скобки задают порядок
действия логических операторов. По запросу "быстрый ИЛИ качественный
поиск" будут выданы документы, содержащие либо слово "быстрый", либо
одновременно слова "качественный" и "поиск" (оператор
И действует первым). По запросу "(быстрый ИЛИ
качественный) поиск"
будут выданы документы, где встречаются одновременно слова "быстрый"
"поиск", либо "качественный" и
"поиск". |
Поддерживается поисковая функция усечения, при этом ключевое слово вводится со знаком "*" для замены любого количества букв в конце слова.
Система осуществляет поиск с учетом морфологических форм ключевых слов. Например, по запросу "человек шел" будут найдены среди прочих и документы, содержащие текст "люди идут". В некоторых случаях использование такой функции может привести к выдаче большого количества нерелевантных документов за счет совпадения морфологических форм различных по смыслу слов. Так, например, слово "пар" – это форма именительного падежа единственного числа существительного мужского рода и форма родительного падежа множественного числа существительного женского рода "пара" (в смысле двойка). Для снятия подобной неоднозначности используется специальный оператор "!", который ставится перед ключевым словом. Так, по запросу "!пар" не будет находиться словоформа "парой", имеющаяся только у существительного женского рода "пара".
Апорт поддерживает поиск по фразе, которая заключается в кавычки. Также в запросе возможно использование оператора близости "сл". Он задает общее количество слов во фрагменте с искомыми ключевыми словами. Например, по запросу "сл20(библиотеки архивы информационные центры)" будут найдены документы, содержащие все указанные ключевые слова в произвольном порядке, но общее число находящихся между ними слов не будет превышать 20. Синонимами оператора "сл" являются "с", "w" и квадратные скобки.
Операторы расстояния
|
Оператор |
Синонимы |
Описание |
|
" |
' ' |
Двойные или одинарные кавычки
позволяют находить словосочетание, указанное в них, или близкое к нему.
Последняя оговорка связана с двумя обстоятельствами. Во-первых, стоп-слова в кавычках игнорируются, как и в обычном
запросе. Во-вторых, грамматическая форма слов также кавычками не
фиксируется. Пример: по запросу "яблоки на
снегу" будут найдены
документы, содержащие следующие фрагменты: "яблоки на снегу", "яблоки и
снег", "яблокам под снегом", "яблоко снег" и
т.п. |
|
сл2 |
с2(...) |
Ограничение расстояния в словах
(двойка указана как пример). Если вы хотите потребовать, чтобы заданные
вами слова встречались, скажем, в пределах 5 слов, то надо написать:
"сл5(папа мама сын)". При этом будут найдены
документы, где между словами "папа", "мама" и "сын" стоит не более двух
других слов (то есть общее число слов во фрагменте не более 5). Порядок, в
котором встречаются заданные слова, не
важен. |
Система поддерживает поиск не только в текстовой части html‑документа, но и в других его разделах. Для этого используются следующие специальные операторы.
Поиск по адресам
|
Оператор |
Синонимы |
Описание |
|
url= |
url: |
Данный оператор позволяет
получить список документов, проиндексированных Апортом на заданном сайте. Например, по запросу "URL=www.intel.ru" будут выданы
все документы, проиндексированные Апортом на сайте
www.intel.ru. |
Поиск по полям
Оператор |
Описание |
|
title= |
Указанное после равенства слово
или конструкция в круглых скобках должны искаться в заголовках документов
(перед круглыми скобками знак равенства можно опускать). По запросу
"title=(папа или мама)" будут найдены документы,
содержащие в заголовке слово "папа" или слово "мама", или оба слова
одновременно. |
|
keywords= |
Указанное после равенства слово
или конструкция в круглых скобках должны искаться в поле META KEYWORDS
документов (перед круглыми скобками знак равенства можно опускать). По
запросу "keywords=(папа и мама)" будут найдены документы, для
которых автор в ключевых словах указал оба слова: "папа" и "мама". |
|
alt= |
Указанное после равенства слово
или конструкция в круглых скобках должны искаться в полях ALT (комментарии
к картинкам). По запросу "alt=(Билл Гейтс)" будут найдены
документы, в которых есть картинка с комментарием, содержащим как минимум
два слова: "Билл" и "Гейтс". |
|
anchor= |
Указанное после равенства слово
или конструкция в круглых скобках должны искаться в тексте ссылок. По
запросу "anchor=(люблю Интернет)" будут найдены документы, в тексте
ссылок на которые, встречаются оба слова: "любить" и "Интернет". |
|
description= |
Указанное после равенства слово
или конструкция в круглых скобках должны искаться в тексте описаний сайтов
каталога Апорта и в поле META DESCRIPTION документов. По запросу
"description=(уксусная кислота)" будут найдены корневые документы
сайтов, в тексте описаний которых встречается словосочетание "уксусная кислота", а также
документы, в которых это словосочетание встречается в поле META
DESCRIPTION. |
|
text= |
Указанное после равенства слово
или конструкция в круглых скобках должны искаться только в обычном тексте.
По умолчанию слова запроса ищутся как в тексте, так и во всех указанных
выше полях. Чтобы искать только по тексту, выдаваемому в основное окно
браузера, следует использовать данный оператор. По запросу
"text=(оглавление или содержание)" будут найдены документы, в
которых любое из указанных слов встречается в пределах основного текста
документа. |
|
link= |
Поиск в URL-адресах ссылок,
имеющихся в html‑документах (можно искать только полное имя сервера до
первой косой черты). |
Оператор "url" можно комбинировать с ключевыми словами, например: по запросу "url=www.nlr.ru AND электронные AND коллекции" будут выданы документы с сайта РНБ, содержащие слова "электронные" и "коллекции". При поиске с использованием операторов "title=", "keywords=", "alt=", "anchor=", "description=" и "text=" несколько ключевых слов заключаются в кавычки, например: "keywords =(библиотеки NOT архивы)".
Результаты поиска и дополнительные возможности
В начале страницы с результатами поиска указывается количество
найденных по запросу сайтов, а в скобках число содержащихся в них релевантных
документов. Все найденные документы сортируются по степени релевантности.![]() Задача
ранжирования результатов поиска является определяющей с точки зрения качества
работы поисковой системы. Разработка хорошей функции ранжирования весьма
непростая задача, в частности, из-за большой неоднородности ранжируемых
документов и из-за попыток сознательного искажения результатов поиска с помощью
поискового спама. Мощным средством повышения качества ранжирования является учет
гипертекстовой структуры Интернета: ссылочное ранжирование и индекс цитируемости
позволяют (хотя и не всегда) отличить качественный контент от сходного по
содержанию "мусора", а также (что особенно важно для владельцев сайтов)
оригинальные материалы от их копий. Однако и здесь приходится иметь дело с теми
же проблемами: неоднородностью ссылочной структуры и ее сознательным искажением
спамерами.
Задача
ранжирования результатов поиска является определяющей с точки зрения качества
работы поисковой системы. Разработка хорошей функции ранжирования весьма
непростая задача, в частности, из-за большой неоднородности ранжируемых
документов и из-за попыток сознательного искажения результатов поиска с помощью
поискового спама. Мощным средством повышения качества ранжирования является учет
гипертекстовой структуры Интернета: ссылочное ранжирование и индекс цитируемости
позволяют (хотя и не всегда) отличить качественный контент от сходного по
содержанию "мусора", а также (что особенно важно для владельцев сайтов)
оригинальные материалы от их копий. Однако и здесь приходится иметь дело с теми
же проблемами: неоднородностью ссылочной структуры и ее сознательным искажением
спамерами.
Ещё одним важным средством повышения релевантности является использование информации из каталога Апорта, которая обладает высокой степенью достоверности, так как составлена или проверена профессионально подготовленными редакторами.
Принципиальным моментом в ранжировании результатов поиска в Апорте является стремление к учёту максимального количества критериев ранжирования в их взаимосвязи. В частности, заметное преимущество получают документы, имеющие высокий вес сразу по нескольким независимым критериям (например, по частотности слов запроса в тексте и ссылочному ранжированию).
Ранжирование производится исключительно автоматическими методами, Апорт не осуществляет специальной корректировки результатов поиска для каких-либо запросов или сайтов.
Критерии ранжирования
Апорт применяет следующие критерии при ранжировании документов:
·
частота и взаимное расположение слов
запроса в тексте документа;
·
размер документа;
·
присутствие и взаимное расположение
слов запроса в выделенном (размером шрифта или html-тегами <b>,
<strong>, <h1>...<h6>) тексте;
·
присутствие и расположение слов
запроса в заголовке документа;
·
присутствие и расположение слов
запроса в мета-тегах "keywords" и "description";
·
присутствие и расположение слов
запроса в ссылках на ранжируемый документ и авторитетность этих ссылок;
·
присутствие и взаимное расположение
слов запроса в названии и описании сайта в каталоге Апорта (учитывается при
вычислении веса главной страницы сайта);
·
взвешенный индекс цитирования
документа;
·
количество страниц сайта, имеющих
высокую релевантность запросу.
Результирующий
вес документа рассчитывается по специальному алгоритму, различным образом
учитывающему сочетания разных критериев.
Частотные характеристики
Учитывается как абсолютная, так и относительная частота слова в тексте документа.
И для той
и для другой величины существуют пороговые значения, после достижения которых дальнейшее увеличение частоты не влияет на
вес документа. Для небольших документов, размер которых (в словах) меньше
заданной константы, относительная частота рассчитывается не от их фактического
размера, а от этой константы.
В
заголовке, мета-тегах, а также в названии и описании сайта из каталога частота
слов не учитывается.
Ссылочное
ранжирование
Алгоритмы
ссылочного ранжирования в Апорте учитывают не более одной ссылки с каждого
домена второго уровня для отдельного запроса (то есть, для разных запросов могут
учитываться разные ссылки).
Вес
каждой ссылки зависит (помимо ее текста) от взвешенного индекса цитирования
ссылающейся страницы.
Взвешенный индекс цитирования
Алгоритм
вычисления взвешенного индекса цитируемости является модификацией классического
алгоритма PageRank. Индексом цитирования сайта считается взвешенный индекс
цитирования страницы, самый высокий среди всех страниц сайта (в большинстве
случаев это бывает взвешенный индекс цитирования главной страницы сайта).
Мета-теги
"keywords" и
"description"
Ключевые
слова (meta keywords) учитываются Апортом даже в случае их отсутствия в тексте
документа. Индексируется не более 16 ключевых слов для каждого документа.
Мета-тег "description" также учитывается при ранжировании, однако, в большинстве
случаев, имеет очень небольшой вес.
Результаты
поиска представлены в виде заголовка документа, URL-адреса и описания сайта,
кроме этого пользователю предоставляются сведения о дате создания документа, его
размере в килобайтах и виде кодировки (рис. 3. 23).
Рис.
3. 23. Формат выдачи результатов поиска "рождественские подарки" в
поисковой системы Апорт
На рис. 3. 23 введены
обозначения:
1.
Закладки, с помощью которых можно
переключаться между различными видами поиска;
2.
Ссылка на результаты поиска по
новостным ресурсам для заданного запроса (в скобках указано число найденных
новостей);
3.
Ссылка на новость наиболее
релевантную заданному запросу;
4.
Число результатов поиска по запросу;
5.
Название и ссылка на найденный сайт;
6.
Описание сайта, составленное
редактором (импортируется из Апорт-каталога);
7.
Название и адрес наиболее
соответствующего (самого релевантного) запросу документа на сайте;
8.
Цитаты из полного текста документа с
выделением слов запроса;
9.
Ссылка на сохраненный текст документа
(полезно, если сам сайт не доступен через Интернет);
10.
Адрес найденного сайта;
11.
Рубрики из каталога на тему запроса;
12.
Ссылка на результаты поиска по данному сайту (все найденные страницы);
13.
Страна или регион России, к которому
принадлежит найденный сайт. При клике по ссылке будет произведен поиск по
запросу с ограничением области поиска сайтами из этого региона;
14.
Ссылка на рубрику Апорт-каталога, к
которой относится найденный сайта (если сайт опубликован в каталоге);
15.
Страна или регион России, к которому
относится ваш IP-адрес. При клике по ссылке будет произведен поиск по запросу с
ограничением области поиска сайтами из этого региона;
16.
Рекламные ссылки, соответствующие
запросу (контекстная реклама).
Первое,
что видно в окне ‑ кроме числа найденных документов, Апорт выдает число
найденных сайтов. Это не просто формальная процедура, дальше вся выдача разбита
именно на сайты, а не на документы. Это вовсе не означает, что нельзя искать
отдельные документы ‑ результаты поиска устроены так, чтобы совместить общую
информацию и детальные данные.
Сайты
Тут важно пояснить, что
Апорт понимает под сайтом. Многие зарубежные поисковые системы так или иначе оперируют понятием сайта, но
подразумевают под этим просто адрес сервера типа www.server.com. В этом случае
адрес сайта определяется из адреса страницы простым отрезанием хвоста: из
http://www.server.com/users/~vasya получается сайт www.server.com. Для больших
серверов, где размещены сайты множества фирм или людей, это неудачное решение
(достаточно сказать, что из только около трети сайтов в российском Интернете
являются самостоятельными серверами). Апорт берет в качестве сайта сервер только
в самом крайнем случае. Как правило, для определения того, какая группа страниц
является логическим целым (сайтом) Апорт использует
информацию из базы данных каталога @Rus (эт-рус) или из своей регистрационной
базы. И в том, и в другом случае информация о сайте вводится человеком, а потому
гораздо точнее, чем-то, что дает любой автоматический алгоритм (специальные
алгоритмы тоже используются, но только, если сайт не зарегистрирован в @Rus или
Апорте).
Использование
регистрационной информации о сайте дает, кроме прочего, сведения общего
характера: описание сайта, категории, к которым он относится. Вспомогательные
данные подобного рода приводятся в левой части экрана (6). Довольно полезно
понимать, какая часть страниц сайта соответствует запросу. Это легко оценить из
информации о числе найденных на сайте страниц и общем количестве страниц сайта
(7).
Документы
Апорт дает весьма
информативное представление найденных при поиске страниц. В блоке каждого сайта
Апорт приводит информацию об одной (самой подходящей) из найденных на сайте
страниц (8). При этом кроме типичного для поисковых машин джентльменского набора
(адрес, заголовок, размер и дата файла, и т.п.) Апорт выдает цитаты из документа
(9). Важно, что цитаты выбираются из полного текста документа и содержат слова,
которые вы искали. Читая цитаты, зачастую легко понять, интересует вас документ
или нет. Это очень удобно.
Как и в предыдущей
версии Апорта, имеется ссылка на реконструкцию полного текста документа. Она
нужна, если документ недоступен на самом сайте (упал
сервер, документ уже удалили и т.п.). В новой версии Апорта реконструкция текста
сделана более читаемой, она содержит больше элементов
форматирования из оригинального документа.
Если вы хотите заняться
сайтом более плотно (желаете получить информацию обо всех остальных страницах,
которые Апорт нашел на нем), то можете воспользоваться ссылкой, которая замыкает
блок результатов. По этой ссылке выдается дополнительное окно, в котором
открываются результаты поиска только по данному сайту. Они состоят из блоков
данных по отдельным страницам. Формат представления информации по каждой
странице аналогичен блоку 8.
Апорт предлагает дополнительные
функции, такие как
·
Поиск
новостей – поиск
новостной информации, предоставленной нашими партнерами – ведущими российскими
СМИ.
·
Поиск
mp3-файлов – поиск
файлов в форматах *.mp3, *.ra и *.mid[i], размещенных на сайтах Рунета. В
результатах поиска представляется ссылка на найденный файл и на сайт
источник.
·
Поиск
рефератов – поиск
рефератов по базе данных сайта www.referat.ru.
·
Поиск
знакомств – поиск
анкет по базе данных знакомств сайта www.omen.ru.
·
Поиск
работы – поиск
резюме и вакансий по базе данных сайта www.zarplata.ru.
·
Поиск по
картинкам – поиск
графических файлов, расположенных на интернет-сайтах.
Rambler (http://www.rambler.ru)
Поисковая система Rambler
представляет собой портал, объединивший поисковую систему, рейтинг-классификатор
Rambler's Top100, а также ряд бесплатных сервисов и информационных проектов.
Ресурсы портала регистрируют ежесуточно более 3,5 млн. посещений, а
ежемесячная аудитория Rambler составляет 60-70% всех
пользователей российского Интернета. Наиболее интересными проектами являются
"Rambler-Наука", "Интерактивные карты" и "Словари". Кроме того пользователям предоставляется возможность проведения
поиска информации на ftp-серверах
(http://ftp.search.rambler.ru:8101/).
Простой поиск
Запрос из ключевых слов вводится в
поисковое окно,
расположенное в верхней части домашней страницы (рис. 3.24). Поисковый
запрос может состоять из одного или нескольких слов, в нем могут присутствовать
знаки препинания. Составлять простые запросы можно, не вдаваясь в тонкости языка
запросов. По умолчанию
используется логический оператор "AND". Так,
если ввести в поисковую строку несколько слов без знаков препинания и логических
операторов, будут найдены документы, содержащие все эти слова (причем на
ограниченном расстоянии друг от друга).
![]()
Рис. 3.24. Поле для ввода ключевых
слов поисковой системы Rambler
Каждый
запрос, адресованный поисковой системе Rambler, обрабатывается в соответствии с
правилами языка запросов. Некоторые слова и символы трактуются как операторы
языка запросов и обрабатываются специальным образом. Фактически, языком запросов
описывается некая формула, которая используется при поиске – каждый из
документов "сопоставляется" с ней, и результатом поиска являются только те
документы, которые ей удовлетворяют.
Например,
запросу "самолет"
удовлетворяют все документы, в которых хотя бы раз встретилось слово "самолет" в любой форме. Запросу,
состоящему из нескольких слов, удовлетворяют документы, содержащие каждое из
этих слов в любой форме (при некоторых условиях). Вопрос соответствия документа
более сложному запросу определяется логикой операторов и конструкций языка
запросов.
В общем
случае, регистр написания поисковых слов и операторов значения не имеет, то есть
дом и ДОМ, Not и nOt воспринимаются одинаково. И лишь
иногда, в целях повышения качества поиска, регистр слов
поискового запроса принимается во внимание.
Например,
если запрос состоит из двух, трех или четырех слов, каждое из которых написано с
большой буквы, то предполагается поиск по имени собственному, и автоматически
производится изменение ограничения расстояния между словами запроса со значения
по умолчанию на величину (n-1)*2, где n – количество слов запроса. Это позволяет
находить группу слов запроса, внутри которой есть не более одного "лишнего"
слова или знака препинания, например "Баден-Баден", "А. Пушкин", "Федор
Михайлович Достоевский".
Запрос,
состоящий из нескольких слов, может содержать операторы. Поиск операторов в
документе не производится, они служат лишь инструкцией поисковой машине. Все
операторы поисковой машины бинарные, то есть имеют левую и правую часть, каждая
из которых также является запросом (по умолчанию состоящим из одного слова). Для
изменения сферы действия операторов (группировки нескольких слов запроса в
аргумент оператора) применяются скобки и кавычки.
Два
запроса, соединенные оператором AND
(логическое И) образуют сложный запрос, которому
удовлетворяют только те документы, которые одновременно удовлетворяют обоим этим
запросам. Иными словами, по запросу "собака AND кошка" найдутся
только те документы, которые содержат и слово "собака", и слово "кошка".
Сложному
запросу, состоящему из двух запросов, соединенных оператором OR (логическое ИЛИ) удовлетворяют все документы,
удовлетворяющие хотя бы одному из этих двух запросов. По запросу "собака OR
кошка" найдутся документы, в
которых есть хотя бы одно из слов "собака" или "кошка" (либо оба эти слова
вместе).
Оператор
NOT (логическое И-НЕ)
образует запрос, которому отвечают документы, удовлетворяющие левой части
запроса и не удовлетворяющие правой. Так, результатом поиска по запросу
"собака NOT кошка" будут
все документы, в которых есть слово "собака" и нет слова "кошка".
Если
оператор явно не указан, используется оператор по умолчанию AND: находятся только документы,
содержащие все слова запроса. Так, запрос "информация технологии
кредит" будет истолкован как
"информация AND технологии AND кредит". На странице Расширенного поиска оператор по
умолчанию можно заменить на OR.
Операторы
AND и OR имеют сокращенные обозначения:
|
Оператор |
Сокращенное
обозначение |
|
AND |
& |
|
OR |
| |
Запрос из
нескольких слов, перемежающихся операторами, будет истолкован в соответствии с
их приоритетом. Операторы AND и NOT традиционно имеют более высокий
приоритет, поэтому запрос из нескольких слов при обработке сначала группируется
по операторам AND и NOT, и лишь потом по операторам OR. Изменить порядок группировки можно
использованием скобок.
Для
поиска цитат можно использовать двойные кавычки. Слова запроса, заключенного в
двойные кавычки, ищутся в документах именно в том порядке и в тех формах, в
которых они встретились в запросе.
Таким
образом, двойные кавычки можно использовать и просто для поиска слова в заданной
форме (по умолчанию слова находятся во всех формах). Например,
запросу "самолет "заправился" посадка" удовлетворяет документ, содержащий
текст "... самолет совершил посадку и
заправился ...", и не удовлетворяет документ, содержащий "... самолет совершил посадку,
чтобы заправиться ...".
При
построении запросов иногда возникает необходимость объединения слов запроса в
группы, которые будут аргументами некоторого оператора. Такие группы заключаются
в скобки.
Часть
запроса, заключенная в скобки, сама является запросом, и на нее распространяются
правила языка построения запросов. Использование скобок позволяет строить
вложенные запросы и передавать их операторам в качестве аргументов, а также
перекрывать приоритеты операторов, принятые по умолчанию.
Если
запрос без скобок "машина самолет | аэродром" эквивалентен запросу "машина AND
самолет OR аэродром" и, в
соответствии с приоритетами операторов, означает найти документы, содержащие
либо слова "машина" и "самолет", либо слово "аэродром", то
запрос со скобками "машина (самолет|аэродром)" равносилен запросу "машина AND (самолет OR
аэродром)", что означает найти документы, содержащие слово "машина" и одно из слов "самолет" или "аэродром".
Rambler
поддерживает поисковую функция усечения слова справа: символ "*", стоящий
в конце слова заменяет любое количество букв. Символ "!" в начале слова или
фразы означает исключающееся слово или фразу. Повторно "!" в таких фразах не
допускается. Исключающиеся слова следует размещать в конце фразы, а исключающие
фразы — в конце запроса. Например, запросы со словосочетанием "телефонн* номер*", но без слов "сотов*"
и "мобил*" записываются как "телефонн*+номер*+!сотов*+!мобил*", запросы со словосочетанием "телефонн* номер*" и со словом
"оператор", но без слова "сотов*" – "телефонн*+номер*+оператор+!сотов*". А запросы со словосочетаниями
"телефонн* номер*" или "оператор" и без слов(фраз)
"сотов*" и "мобил*" можно написать следующим образом: "телефонн*+номер*+оператор*+!сотов*+!мобил*".
По
каждому слову запроса поиск ведется с учетом правил словоизменения
соответствующего языка. Rambler понимает
и различает слова русского и английского языков – по умолчанию, поиск ведется по
всем формам слова.
Например,
при поиске по слову "человек" будут также найдены документы,
содержащие слова "человеку", "человеком",
"человека" и даже "люди". Чтобы
провести поиск только по одной определенной форме слова, нужно взять его в
двойные кавычки или воспользоваться поиском точной фразы в расширенном поиске.
Поиск морфологических
форм задается оператором "#", а поиск однокоренных оператором "@".
Некоторые
слова и символы по умолчанию исключаются из запроса в связи с их малой
информативностью. Это так называемые стоп-слова – самые
частотные слова русского и английского языков, например, предлоги, частицы и
артикли. Присутствие этих слов может замедлить поиск и негативно повлиять на
полноту результатов. Есть возможность обозначить необходимость этих слов в
запросе, взяв запрос в двойные кавычки или воспользовавшись поиском точной фразы
в расширенном поиске.
Если
запрос состоит из нескольких слов, и при этом некоторые из них вообще не удалось
найти в Интернете, то выдаются результаты поиска по частичному запросу, из
которого отсутствующие в Интернете слова исключены. При этом на странице
результатов поиска выдается соответствующая диагностика.
Ограничение расстояния
Если
запрос составлен из одного или нескольких слов без применения операторов и
конструкций языка запросов, то будут найдены документы, в которых встречаются
все слова запроса. При этом для каждого запроса всегда существует так называемое
ограничение контекста – положительное число, по умолчанию равное расстоянию в 40
слов. Документ, в котором встретились все слова запроса, будет выдан только в
том случае, если расстояние в словах между вхождениями слов запроса будет меньше
этого числа. Например, по запросу "красная армия" будут найдены те документы, в
которых слова "красная" и "армия" хотя бы один раз встретятся
менее чем в 40 словах друг от друга.
Значение
ограничения контекста можно изменять конструкцией "(число, запрос)", где число – любое положительное
число, запрос – любой корректный с точки зрения поисковой машины запрос,
состоящий более чем из одного слова (очевидно, ограничение расстояния между
словами в случае однословного запроса не имеет смысла). Таким образом, по
запросу "(2, красная
армия)" найдутся
только те документы, в которых между словами "красная" и "армия" хотя бы раз не стоит ни одного
слова (поскольку лишь в случае их непосредственного соседства разница в
порядковых номерах слов меньше 2, т.е. равна 1)
Rambler
позволяет искать страницы, на которых размещены счетчики Top100, TopShop
(http://topshop.rambler.ru/),
TopList (http://top.mail.ru/),
SpyLog (http://www.spylog.ru/), а
также HotLog (http://www.hotlog.ru/). Для того
чтобы найти в Итернете все страницы, на которых размещен
счетчик с заданным идентификатором, используйте оператор "${counter=ID}", где counter – название счетчика
(top100, topshop, toplist, spylog или hotlog), а ID – номер счетчика
(идентификатор ресурса). Например, для того, чтобы найти в Интернете все
страницы раздела Rambler-Открытки
(http://cards.rambler.ru/) (идентификатор Top100 – 193680), задайте запрос "${top100=193680}".
При составлении запроса можно
использовать следующие специальные операторы:
·
$All – поиск во всех разделах
html-документа;
·
$URL – поиск в
URL-адресе html-документа;
·
$Title – поиск в заголовке
html-документа;
·
$Essence – поиск в аннотации к
html-документу.
Расширенный поиск
Переход на страницу расширенного
поиска осуществляется с домашней страницы щелчком по ссылке "Расширенный поиск". Интерфейс страницы
расширенного поиска содержит поле для ввода ключевых слов и шаблон, состоящий из
нескольких фильтров для уточнения запроса (рис. 3.23), которые дают
возможность:
·
задавать дополнительные параметры
поиска;
·
редактировать параметры поиска и
поля, заданные по умолчанию;
·
выбирать наиболее
удобную форму показа результатов поиска.
Поиск по тексту ...
·
всего
документа – поиск
осуществляется по всему документу, включая его название и заголовки; включено по
умолчанию;
·
названия –
учитываются только названия документов (тег
<title>);
·
заголовков –
учитываются только заголовки документов (теги <h1>, <h2>,
<h3>, <h4>)
Искать
слова запроса ...
·
все
("и") –
документ находится только в том случае, если в нем присутствуют все слова
запроса; включено по умолчанию;
·
хотя бы
одно ("или") –
документ находится, если в нем встретилось хотя бы одно слово из
запроса;
·
точную
фразу –
документ находится, если в нем встретились все слова запроса, причем в том же
порядке и в тех же формах, что и в запросе; выбор этой опции равнозначен
заключению поискового запроса в двойные кавычки.
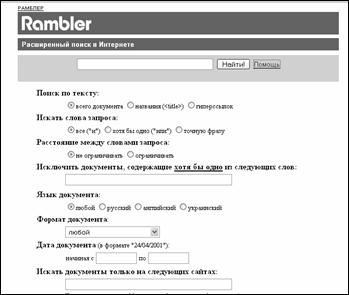
Рис.
3.23. Окно расширенного поиска в поисковой системе Rambler
Расстояние между словами запроса ...
·
ограничивать –
расстояние между словами из запроса в тексте документа не должно быть слишком
большим; включено по умолчанию, поскольку повышает точность
поиска;
·
не
ограничивать –
расстояние между словами не играет роли; будут найдены все документы, содержащие
слова запроса, вне зависимости от того, на каком расстоянии друг от друга они
находятся.
Исключить
документы, содержащие следующие слова ...
Из списка
найденного исключаются те документы, в которых есть слова, перечисленные в этом
поле.
Язык документа ...
·
любой –
находятся любые документы, независимо от языка; включено по
умолчанию;
·
русский – поиск
только по "русскоязычным" (кириллическим) документам;
·
английский – поиск
только по "англоязычным" документам (набранным латиницей).
Дата документа ...
Позволяет
отбирать только те документы, дата создания которых укладывается в заданный
диапазон. В частности, можно ограничить выдачу только "новыми" (начиная с
указанной даты) или "старыми" документами (до указанной даты). Все даты задаются
в формате день/месяц/год, например, 29/02/2000. По умолчанию
находятся любые документы, вне зависимости от даты. Если сервер не возвращает
даты документа, то в качестве таковой проставляется дата индексирования (день,
когда документ был считан "пауком" Rambler'а).
Искать документы
только на следующих сайтах ...
Позволяет
отбирать только те документы, которые найдены на указанных сайтах. Под сайтом понимается либо уникальное DNS-имя (домен), либо DNS-имя c каталогом первого
уровня, начинающимся с тильды. Например:
top100.rambler.ru,
www.lenta.ru, www.hosting.ua/~name - но
не www.rambler.ru/domains/.
Можно
указать несколько сайтов через запятые. По умолчанию в поиске участвуют
документы со всех проиндексированных сайтов.
Результаты поиска
По умолчанию найденные документы
сортируются по степени релевантности. Каждая страница может содержать от 15 до
50 ссылок на найденные документы. Полный формат выдачи результатов поиска
состоит из следующих элементов: URL -адрес сайта, заголовок документа, выдержка
из текста страницы с выделенными жирным шрифтом ключевыми словами, дата создания
или последнего обновления документа, размер в килобайтах, указание на вид
кодировки и ссылка "Найти похожие" для поиска документов, наиболее релевантных
данному (рис.3.25).
Рис. 3.25. Формат выдачи результатов
поиска поисковой системы Rambler
Кроме того,
указываются сведения о том, сколько всего найденных документов содержится на
данном сайте, даются ссылки на первые три из них и список остальных
документов.
Вывод
результатов поиска
1.
Сортировать
...
· сайты по
релевантности –
найденные документы группируются по сайтам, так что одна позиция в списке
результатов поиска может соответствовать нескольким документам; порядок выдачи
сайтов определяется их релевантностью (степенью соответствия запросу документов
с сайта); включено по умолчанию;
· страницы
по релевантности –
документы не группируются по сайтам, то есть все документы с одного сайта
выдаются по отдельности; порядок выдачи определяется релевантностью
(соответствием запросу) каждого отдельного документа;
· страницы
по дате (сначала новые) –
документы не группируются по сайтам; порядок выдачи – от более новых документов
к более старым;
· страницы
по дате (сначала старые) – то же,
что и в предыдущем случае, но сначала выводятся самые старые из найденных
документов.
2.Выдавать
...
· по
15 – на
страницах результатов поиска выводится по 15 найденных документов (сайтов);
включено по умолчанию;
· по
30 –
количество позиций на страницах результатов поиска увеличивается до
30;
· по
50 –
количество позиций на страницах результатов поиска увеличивается до
50.
3.Форма
вывода ...
· стандартная
– включено
по умолчанию;
· краткая – в
результатах поиска показываются только заголовки найденных
документов;
· детальная
–
выводится максимум информации о найденных документах: заголовок, аннотация,
идентификатор документа, даты модификации и индексирования, размер, кодировка,
адрес, и т.п.
4.Связанные
запросы ...
· показывать – в
левой части экрана выводится список запросов, "связанных" с данным – то есть часто задаваемых
теми пользователями, которые вводили данный запрос;
· не
показывать –
включено по умолчанию; колонка со списком "связанных" запросов не выводится (начало списка показывается внизу страницы под
заголовком "У нас также ищут").
Комфортный поиск
Для
облегчения поиска в Интернете можно установить на панель своей программы
(Netscape или Internet Explorer версии не ниже 4) специальную кнопку поиска в
Rambler. Чтобы это сделать необходимо на странице помощь Комфортный поиск, перетащить мышкой
соответственную ссылку Искать в Rambler в поле
панели ссылок. После этого на панели появится кнопка "Искать в Rambler". При
этом в браузере должно быть разрешено выполнение JavaScript.
Если во
время просмотра документа будет выделен текст, который необходимо задать в
качестве поискового запроса, и при нажатии на эту кнопку, запрос будет передан
Rambler. Результаты поиска в
поисковой системе будет выведены в другом окне. Длина запроса ограничена 96
символами.
На сегодняшний день объем
проиндексированных в базе поисковой системе документов составляет более 33
миллионов. Поиск осуществляется не только по Web-страницам, но и по
специализированным массивам данных, среди которых новости ведущих информационных
агентств, товары Интернет-магазинов, ресурсы WAP-серверов, а также каталог
Интернет-ресурсов List.ru.
Поисковая система поддерживает
собственный каталог Интернет-ресурсов, формирующийся на основе индекса
цитирования Яndex'а (CY-Citation Yandex). CY какой-либо
Web-страницы
измеряется количеством других страниц, содержащих ссылки на эту страницу. Этот
метод оценки ресурсов принципиально отличается от простого учета количества
посещений страницы.
Поисковая система Яndex имеет простой
и расширенный поисковые интерфейсы, а также страницу настройки
формата выдачи результатов поиска. Система использует собственную систему
обозначений логических операторов, а также поддерживает большое количество
поисковых функций, позволяющих составлять запросы различной степени
сложности.
Простой поиск
Язык запросов Яndex состоит из операторов, которые отделяются от слов пробелами и могут располагаться перед, после и между словами, а также знаков, которые помещаются непосредственно перед словами без разделяющих пробелов.
В верхней части домашней страницы
поисковой системы расположено поле для ввода ключевых слов (рис. 3.26). По
умолчанию слова запроса связываются оператором OR . Над поисковым полем
приводится пример формулировки запроса, меняющийся при каждом новом открытии
страницы простого поиска. Селекторные кнопки снизу позволяют ограничивать поиск
следующими областями: "новости", "товары" и "картинки".
![]()
Рис. 3.26. Поле для ввода ключевых
слов поисковой системы Яndex
Система различает слова, набранные
строчными и прописными буквами. Поддерживается поиск по фразе, которая
заключается в кавычки.
Операторы "+" и
"-"
Перед ключевым словом допускается
постановка знаков "+" и "-": Яndex позволяет исключать
страницы, где есть определенные слова. Для этого используются "~" – бинарный
оператор И НЕ (в пределах предложения) и "~~" или "-" бинарный оператор
И НЕ (в пределах документа).
Например, если вам нужно описание
Парижа, а не предложения многочисленных турагентств, задайте запрос
"путеводитель по Парижу ~агентство ~тур". Если вы ищете информацию о Задорнове (но не
министре), тогда можете задать запрос "Задорнов ~~ министр". Будут найдены все страницы, где
есть слово "Задорнов" и нет
слова "министр".
Чтобы строго обеспечить появление
слов в предложении, надо перед ними поставить знак "+", например так: "+Буш +Гор +выборы". Знак "+" должен записываться слитно
с тем словом, к которому относится (без пробела).
Логическое И
Если слова запроса разделены
оператором "&" (логическое И) – это означает, что в результаты поиска
попадут те документы, в которых все указанные слова присутствуют в одном
предложении. Например, запрос "книжный
& магазин" возвратит те документы, где говорится о книжных магазинах, и
не станет возвращать те, в которых в одном месте говорится о книжной ярмарке, а
в другом – о магазине сп??рттоваров. Оператор "&" используется по умолчанию,
так что запрос "книжный магазин"
полностью эквивалентен запросу "книжный
& магазин".
Если же требуется одновременное
присутствие слов не только в предложении, но и во всем документе, применяется
оператор "&&" (логическое И в пределах
документа), например: "+Буш
&&+Гор &&+выборы".
Логическое
ИЛИ
Вертикальная черта "|" позволяет задать альтернативы:
система ищет хотя бы одно из перечисленных слов. Например, если вы хотите найти
страницы, где встречается одно из слов "папа", "мама", "дочка", "внучка",
поисковый запрос будет выглядеть следующим образом: "папа | мама | дочка |
внучка".
Оператор "||" – функционируют
полностью аналогично оператору "|" – за исключением того, что "двойной" оператор
работает на уровне документа в целом.
Поиск точного
соответствия – знак "!"
Поиск ключевых слов производится с
учетом их морфологии. Если необходимо осуществить поиск по точной словоформе, то
перед ним ставится знак "!" без пробела. Запрос "!день" найдет страницы, где слово "день" встречается только в такой
форме. Если одна или несколько форм слова совпадает с другими словами, поиск
может находить лишние страницы. Указав нормальную форму слова с помощью
оператора "!!", вы уберете многие из ненужных страниц. Запрос "!!день" найдет все формы слова – "дня", "дню", "днем" и др., и не найдет форм слова
"деть" (одна из которых
совпадает со словом "день").
Независимо от формы слов, Яndex по-разному учитывает слова, набранные
с маленькой и большой буквы.
Поиск точной
фразы
Если вам нужна точная фраза, то при
поиске заключите фразу в кавычки. В этом случае поисковик выведет только те
страницы, где эти слова располагаются строго рядом. Поэтому, если вас интересует цитата
из "Гамлета", вы можете задать запрос, указав "обязательные" слова в кавычках:
"быть или не быть".
Использование
скобок
Скобки применяются для группировки подзапросов при составлении из них одного сложного запроса. Вы можете строить сколь угодно сложные конструкции, подставляя в каждом из операторов вместо отдельного слова целые выражения, заключая их в круглые скобки. Например, если вы ищете описание мумие, но не хотите наталкиваться на прайсы интернет-магазинов, можете задать такой запрос: "мумие && (лечение | лечебный | болезни)~~(цена | прайс | рубли | доллар | фирма | магазин)". Будут найдены все страницы, где есть слово "мумие", а также любое из слов "лечение", "лечебный" или "болезни", и нет ни одного из слов, перечисленных после оператора "~~".
Задание расстояния
между слов – "/n"
В поисковых системах существует
оператор NEAR
позволяющий находить документы, в которых два слова расположены близко друг к
другу. Определим понятие
"расстояние между словами". Если пронумеровать все слова в документе, то
разница между номерами двух выбранных слов и будет расстоянием между ними. Таким
образом, расстояние между соседними словами равно 1. Расстояние может быть как
положительным, так и отрицательным в зависимости от относительного расположения
выбранных слов в документе.
В поисковой системе Яndex можно конкретно указать, на каком
расстоянии друг от друга эти слова должны находиться, используя операторы "/(n m)" – расстояние в словах (-назад +вперед)
и "&&/(n m)" расстояние в предложениях (-назад +вперед).
n и
m – числа,
соответствующие расстоянию. В простом случае используется форма оператора
"/+n" и "/-n"
Например, оператор "/+1"
соответствует двум словам, идущим подряд, то есть "Microsoft/+1 Windows"
– это то же самое, что и “Microsoft Windows”.
Запрос "Microsoft/-5 Windows" может дать ссылку на документ,
содержащий фразу "Об операционных системах, которые заменят Windows, рассказал ответственный
представитель компании Microsoft".
Запрос "инспектор /+2 налог" вернет только те
ссылки, где словоформа от "налог" расположена точно через слово
после словоформы от "инспектор". Такой запрос аналогичен
запросу "налог /-2 инспектор". В качестве
упрощенного написания оператора
"/+1" можно использовать кавычки, например запрос ""ремонт видеотехники"" аналогичен запросу "ремонт /+1
видеотехники".
По умолчанию все операторы поиска с расстоянием
работают на уровне слов, т.к. в запросе вида "налоговый /+1 инспектор"
подразумевается наличие оператора
"&", то есть "налоговый & /+1 инспектор". Если
заменить оператор
"&" на "&&", то расстояние будет измеряться в
предложениях. Допустим, мы ищем упоминание о банках в связи с ипотекой. Запрос "банк ипотека" слишком ограничен,
запрос "банк && ипотека" слишком
свободен, а запрос "банк && /2 ипотека"
будет в самый раз.
Специальный поиск
Также поддерживаются операторы для
поиска информации, содержащейся в специальных полях заголовков ‚ страниц (каждая
Web-страницы
имеет служебные поля в своем заголовке) или поиск специальных элементов,
входящих в Web-страницы,
например гиперссылок. В системе Яndex команды специального поиска в полях
заголовка начинаются с символа $, а команды поиска отдельных элементов
Web-страниц –
со знака. Все средства специального поиска работают заметно медленнее по
сравнению с обычными.
|
Синтаксис |
Что
означает оператор |
Пример
запроса |
|
$title
(выражение) |
поиск в
заголовке |
$title
(CompTek) |
|
$anchor
(выражение) |
поиск в тексте
ссылок |
$anchor (CompTek
| Dialogic) |
|
#keywords=(выражение) |
поиск в ключевых словах |
#keywords=(поисковая
система) |
|
#abstract=(выражение) |
поиск в
описании |
#abstract=(искалка
| поиск) |
|
#image="значение" |
поиск файла
изображения |
#image="tort*" |
|
#hint=(выражение) |
поиск в подписях
к изображениям |
#hint=(lenin |
ленин) |
|
#url="значение" |
поиск на заданном сайте (странице) |
#url="www.comptek.ru*" |
|
#link="значение" |
поиск ссылок
на заданный URL |
#link="www.yandex.ru*" |
Расширенный поиск
Яndex обладает развитым языком запросов, позволяющим осуществлять тонкий поиск. Для того чтобы воспользоваться широким спектром возможностей, используйте страницу "расширенный поиск", где большая часть настроек Яndex'а задается простым образом. Переход на эту страницу осуществляется с домашней страницы щелчком по ссылке "Расширенный поиск". Интерфейс расширенного поиска поисковой системы Яndex представляет собой шаблон, состоящий из поля для ввода ключевых слов, словарного фильтра и нескольких областей уточнения запроса.
Словарный фильтр содержит три раздела (рис. 3. 27):
·
расположены относительно друг
друга – задается
степень близости между ключевыми словами (подряд, в одном предложении, не очень
далеко, на одной странице) При выборе варианта «не очень далеко» Яndex пытается определить, насколько тесно слова запроса
связаны между собой. Сильно связанные слова ищутся в пределах одного
предложения, менее тесно связанные слова — на расстоянии в несколько предложений и, наконец,
несвязанным словам достаточно встретиться на одной странице, чтобы она была
сочтена соответствующей запросу.;
·
расположение на
странице – позволяет
ограничивать поиска определенной областью html-документа (где угодно, в
заголовке, в тексте ссылки на сайт);
·
употреблены в тексте – позволяет осуществлять поиск с
учетом или без учета морфологических форм слова (в любой форме, точно так, как в
запросе).
.
Рис. 3.27. Словарный фильтр поисковой
системы Яndex
Яndex умеет определять язык документа. Вы можете задать язык документа, где надо провести поиск (рис. 3.28): русский (кириллица) или не русский. В базе Яndex'а находятся только документы русскоязычного Интернета (по умолчанию в поисковую машину вносятся сервера в доменах su, ru, am, az, by, ge, kg, kz, md, tj, ua, uz), а также зарубежные сайты, представляющие интерес для русскоязычного поиска. Так же вы можете указать ограничение выдачи документов по дате (последние две недели, последний месяц, последние 3 месяца, последний год, произвольный диапазон) и формат документа (html, pdf, rtf, doc, xls. Ppt, swf и любой). Дата страницы означает дату создания или последнего обновления.
Далее расположены четыре области уточнения запроса в зависимости от местонахождения документа (например, Владивосток или Россия), наличия или отсутствия в нем определенных ссылок, поиск на определенном сайте и поиск на всех похожих на указанную ссылку сайтах.
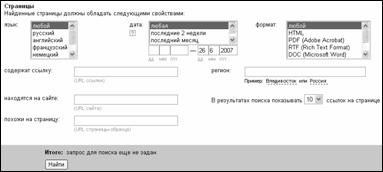
Рис. 3.28. Интерфейс расширенного
поиска поисковой системы Яndex
На странице расширенного поиска имеется также раскрывающееся меню, которое ограничивает отображение количества ссылок на странице в результатах поиска (10, 20, 30, 50 ссылок).
Результаты поиска и дополнительные возможности
Статистика результатов
поиска позволяет узнать количество найденных по запросу страниц и число сайтов,
на которых они располагаются. Эти показатели примерные и могут меняться.
Статистика слов в базе
Яndex'а показывается, только если вы указали это
в настройках. Она говорит о том, сколько раз встретилось каждое из слов
запроса на всех страницах, известных Яndex'у.
Если слово запроса ни разу
не встретилось в базе Яndex'а, оно будет выделено
красным — проверьте, не была ли допущена ошибка в написании.
Если в поиске по запросу участвовали не все
проиндексированные страницы, в области поиска показываются эти ограничения. В их
число входят ограничение по региону, сайту, языку, формату документа, страницы,
похожие на заданную.
Когда запросу соответствуют
рубрики каталога или Яndex.Маркета, перед результатами
поиска выводятся ссылки на соответствующие рубрики. Такое совпадение характерно
для запросов, охватывающих широкую тему (таких как кондиционеры,
открытки), и каталог сайтов или товаров — хорошее место, чтобы найти
сайт с информацией или сделать покупку.
Когда поиск принес мало документов, Яndex анализирует запрос и предлагает способ, которым можно
улучшить результаты.
1.
"Опечатки в запросе?" Если Яndex
подозревает, что в запросе есть опечатка, он может предложить возможный вариант
написания слов. Например, на запрос "муму
подарилиошейник" будет предложено: опечатка? возможно, имелось в виду:
мужу подарили
ошейник
2.
Ничего не найдено? Как правило, небольшое число
документов выдает поиск цитаты, который очень требователен к тексту страницы,
поэтому, задав запрос "люблю грозу в конце апреля", вы увидите сообщение:
"ничего не найдено? попробуйте поискать без кавычек". Ссылка на фразе без
кавычек ведет на результаты поиска по тому же запросу, но уже без кавычек:
"люблю грозу в конце апреля".
Когда запрос отдается на
усмотрение Яndex'а, он ищет слова запроса на таком
расстоянии друг от друга, чтобы максимально повысить качество результатов
поиска. Иногда это приводит к малому количеству найденных страниц. Ссылка «с
более мягкими условиями» ведет на результаты запроса, по которому отобраны
страницы с заданными вами словами, независимо от того, насколько близко они
к друг другу
расположены.
Результаты поиска выдаются в виде заголовка
документа, его описания, URL-адреса, (рис. 3.29). Заголовок документа отражает название
документа, данное ему автором страницы. При нажатии на него
откроется сам документ (в зависимости от настроек, в новом или том же
окне. Если вместо заголовка показывается адрес страницы, значит, ее
заголовок (title) не задан.
Если рубрика содержит более одного релевантного документа, то появляется ссылка "Еще сайты из каталога".
Ссылка внизу страницы "Найти похожие документы" аналогична
ссылке "Похожие документы" в
результатах поиска.
Под
заголовком документа располагается его аннотация, составленная на основе текста,
из которого извлекаются предложения или их части, содержащие слова запроса. Если
Яndex считает такое описание недостаточно
информативным, оно может быть дополнено описанием страницы, которое составил ее
владелец (тег meta description), или заменено на описание сайта из каталога.
Когда сайт найден по ссылкам, в качестве описания
приводятся тексты ссылок.

Рис. 3. 29. Формат выдачи результатов
поиска поисковой системы Яndex
Под описанием документа
выдается информация о нем:
1.
адрес страницы сайта, наиболее
соответствующей запросу;
2.
размер страницы;
3.
дата последнего изменения страницы,
если сервер ее выдает;
4.
мера соответствия страницы запросу.
Возможны три варианта:
·
отсутствие статуса означает, что все
слова запроса есть в тексте страницы;
·
«нестрогое соответствие» появляется,
когда Яndex считает страницу недостаточно
подходящей для ответа на запрос, но так как общее число найденных документов
невелико, он предлагает рассмотреть и такой вариант;
·
«найден по ссылке» говорит, что
страница обнаружена по ссылкам и будет интересна вам, несмотря на то, что она не
содержит слов запроса.
Каждый из элементов
описания может быть спрятан.
Если найденная страница расположена на
сайте, зарегистрированном в каталоге Яndex'а, то под описанием документа
отображается рубрика каталога, которой он принадлежит. Перейдя по этой ссылке, вы попадете в
соответствующий раздел каталога.
Ссылка «Похожие документы» позволяет найти
страницы, которые похожи на выбранную вами и могут
отвечать на запрос столь же хорошо. Если страница-образец уже удалена с сайта,
Яndex выдаст сообщение: «Запрошенный(е) документ(ы) не найден(ы)». По умолчанию ссылка не
показывается, включить ее отображением можно в настройках поиска. Вы также
можете искать похожие документы в форме расширенного поиска.
Ссылка
«Еще с сайта» позволяет увидеть все документы с выбранного сайта, соответствующие запросу
Если вам недостаточно
первых десяти ссылок (или более) на первой странице результатов, вы можете
просмотреть другие страницы. Ссылки «предыдущая» и
«следующая» — переход на страницу, предшествующую или следующую за текущей.
Ряд чисел, оформленных в виде ссылок, позволяет перейти сразу на нужную страницу
результатов поиска. Многоточие в конце списка страниц - переход на страницу,
следующую за перечисленными в
списке.
Вы можете
отсортировать найденные страницы одним из двух способов:
·
по степени их соответствия запросу
(релевантности);
·
по дате последнего изменения
документа.
По умолчанию сортировка
идет по релевантности, а сортировка по дате нужна, как правило, только когда вы
ищете максимально свежие документы.
Если ответ Яndex'а
на ваш запрос оказался недостаточно точным, попробуйте сформулировать запрос
иначе, либо задайте его другим поисковым системам. Достаточно нажать на ссылку с
именем поисковика, и в новом окне откроются его результаты
поиска.
Кроме того описание документа может содержать дополнительные сведения о его размере в килобайтах и о том, в какой форме он содержит слова запроса ("совпадение фразы" или "все слова").
Оператор мягкого поиска "//N".
При формировании списка
результатов поисковая система сортирует их исходя из релевантности. Чем выше релевантность
документа, тем ближе к началу будет его позиция в списке результатов. Факторы,
влияющие на релевантность, обычно сохраняются в строгом секрете.
Обычный запрос вида "слово1 слово2
слово3" возвращает только те документы, в которых все три слова
встречаются в одном предложении. Иногда бывает необходимо получить все
документы, где встречается хотя бы одно из слов, причем более релевантными
должны быть те из них, в которых встречаются все три слова, затем по два, и,
наконец, по одному. Можно решить эту проблему запросом "слово1 | слово2 | слово3", так как
очевидно, что наиболее высокую релевантность будут иметь документы, в которых
есть все три слова. Однако если по какой-либо причине результат такого запроса
вас не устраивает, можно воспользоваться оператором мягкого поиска
"//N". N измеряется в процентах от 0 до 100. Запрос "(слово1 слово2
слово3) //0"
возвращает только документы, содержащие все три слова (как и при отсутствии
данного оператора). В результаты запроса "(слово1 слово2
слово3) //100" будут
включены все документы, в которых встречается хотя бы одно из запрошенных слов.
Варьируя значение N, можно изменять количество найденных
документов.
Язык запросов Яndex также
предоставляет некоторые возможности по изменению релевантности найденных
документов. Не следует забывать, что при этом в результатах поиска содержатся те
же самые документы, а изменяется только их порядок.
Оператор веса ":N"
Оператор веса
":N" позволяет повысить
релевантность документов, содержащих заданное выражение. Например, запрос "физика:1 | химия:1000 | литература:1" возвращает ссылки на
документы, где встречается любой из этих предметов, но документы с упоминанием
химии будут расположены ближе к началу. Чтобы получить заметный эффект,
необходимо указывать достаточно высокие значения N (порядка тысяч и десятков
тысяч).
Оператор уточнения "<-"
При помощи оператора уточнения "<-" можно повысить релевантность тех
документов, в которых встречается уточняющее выражение. Например, по запросу
"(физика | химия) <- библиотека" система
возвратит все документы с упоминанием физики или химии, а первыми в списке
результатов будут расположены документы с упоминанием
библиотек.
В числе дополнительных возможностей,
предлагаемых пользователям поисковой системы Яndex , можно назвать следующие:
интеграция с каталогом Интернет-ресурсов List.ru , поиск по новостным лентам
ведущих информационных агентств, поиск в электронных магазинах и поиск по российским WAP-ресурсам, а также программа "Региональный
Яndex".
Поиск по новостным лентам (http://news.yandex.ru/) ведущих
информационных агентств дает пользователям возможность получить список ссылок на
полный текст информационного сообщения на сайте того или иного агентства. Также
осуществляется доставка последних новостей по интересующей теме по электронной
почте.
Раздел "Яndex.Товары" (http://tovar.yandex.ru/) позволяет
искать необходимые товары как в онлайновых, так и в
обычных магазинах, предоставляющих соответствующую
информацию.
Программа "Региональный Яndex" (http://www.yandex.ru/regions.html)
была создана благодаря сотрудничеству с региональными каталогами.
Теперь
можно ограничивать поиск
ресурсами выбранного региона (Астрахань, Брянск, Владивосток, Воронеж,
Екатеринбург, Иркутск и проч.).
В разделе Яndex.WAP (http://wap.yandex.ru/) предлагается
два вида поиска: по российским WAP-ресурсам и поиск на
территории Москвы. Владелец мобильного телефона, указав свое местоположение
(станцию метро или улицу), сможет узнать адреса ближайших станций техпомощи и
автозаправки, пунктов обмена валюты и банкоматов, гостиниц, театров, кафе и
т.п.
Важная
сфера применения поисковых
технологий
— локальный поиск по отдельному Web-серверу,
который очень актуален для информационно насыщенных серверов (издательские дома,
библиотеки, крупные научные и учебные заведения и т.п.).
Такую
форму поиска можно организовать несколькими способами. Например, можно настроить
поисковую
систему
так,
чтобы данные о Web-узле хранились в общем индексе поисковой системы, а машина
выдавала ссылки только на этот узел. Так работают, например, Rambler и Апорт.
Это решение достаточно простое и бесплатное, но имеет свои ограничения.
Поскольку поиск выполняется на основе индекса поисковой
машины,
меняющегося в лучшем случае раз в неделю, то при такой организации изменения
сервера будут заметны не сразу. Поиск информации на отдельном Web-узле - это та задача, которую приходится решать
каждому пользователю Интернет. Если вы связываетесь с Сетью через модем, то,
очевидно, что, чем больше вы тратите времени на поиски, тем дороже стоит
получаемая информация. В этом случае ее изучение прямо
в Сети становится непозволительной роскошью. Многие предпочитают этому
ознакомительный просмотр и быстрое копирование необходимых материалов, а затем
их более предметное изучение в автономном режиме.
Перенос содержимого сервера целиком на локальный компьютер, а для этого
существуют специальные средства, в большинстве случаев также менее
предпочтителен, чем выборочное копирование. Следовательно, самым полезным
навыком становится умение быстро разобраться в структуре узла и способах
навигации (т. е. путей перемещения с одной Web-страницы узла на другую). Даже
при подключении по выделенной линии, если вы решаете какую-либо поисковую
задачу, и требуется просмотреть десятки узлов из списка отклика поисковой
машины, вопрос о скорости освоения информации остается одним из определяющих.
Рассмотрим два важных для разрешения этой проблемы вопроса.
·
Типовые
структуры размещения информации на Web-узле и возможности навигации
·
Логика
"третьего" уровня и приемы применения автоматических поисковых средств.
4.1. Типовые структуры размещения информации на Web-узле и возможности навигации
Структура
современного Web-узла может быть различной и тесно
связана со способами навигации по его страницам, которых не так уж много, а
именно:
1.
путем
начального задания адреса вручную в строке URL или выбора документа из списка
истории браузера, если таковая уже накоплена;
2.
по
гипертекстовым ссылкам;
3.
по каталогам узла с помощью обрезания
строки ранее введенного адреса (URL).
Каждый
раз при неверном выборе теряется время.
Первый
вариант – это использование кнопок Назад и Вперед панели инструментов браузеров. С
помощью раскрывающегося списка этих кнопок можно выбрать нужную страницу из
списка истории посещений за последний сеанс работы. Можно использовать Журнал.
Второй
вариант является самым неоднозначным. Именно он требует хорошего знания
структуры информационного узла.
Третий
вариант чаще применяется более опытными пользователями. Во многих случаях он
удачно работает тогда, когда вы приходите на узел по ссылке, но указанный в ней
файл не найден. Браузер выдает сообщение типа "File Not Found" или отрабатывает
специальная программа-скрипт, приносящая извинения разработчика сайта (вместо
слова "узел" часто также употребляется термин "сайт", от английского "site") и
предлагающая пользователю другие возможности найти информацию самостоятельно.
Например,
вы обратились к ресурсу по URL
"http://server.citmgu.ru/internet/cources/search1.html".
Искомый
файл search1.html должен находиться на сервере с доменным именем
server.citmgu.ru в каталоге cources, который в свою очередь является
подкаталогом каталога internet, лежащего в корне сервера. Предположим, что
ресурс не найден. После чтения в окне браузера появляется надпись типа "File Not
Found". Это в первую очередь признак того, что сервер работает, а сам документ
мог быть перемещен, переименован или заменен аналогичным по содержанию. В этом
случае надо попытаться выйти на головную (домашнюю) страницу узла и разыскать
файл самостоятельно или с помощью локальной поисковой системы. Для этого в URL
следует убрать часть адреса с правой стороны и нажать на "Enter", т.е.
ввести "http://server.citmgu.ru/internet/cources", а в случае повторной неудачи
– "http://server.citmgu.ru/internet", и так вплоть до собственно доменного имени
сервера "http://server.citmgu.ru".
При таких
обращениях к каталогам сервера, о которых мы узнаем по длинному адресу,
серверная программа может отобразить как список файлов указанного каталога, так
и конкретную Web-страницу, относящуюся к этому каталогу и предназначенную для
загрузки по умолчанию. При этом переходить сразу к имени сервера, минуя
промежуточные обращения, не всегда целесообразно, поскольку, если на сервере,
скажем, размещается несколько домашних страниц отдельных пользователей или
компаний, то всякая логическая связь между ними, вполне вероятно, отсутствует.
Корневой каталог сервера может при этом наполнять еще одна более крупная
компания или организация, которая не имеет никакого отношения к документам,
лежащим в глубине дерева каталогов и никаких ссылок на эти документы.
Следовательно, при отсутствии дополнительной информации лучше идти мелкими
шагами, последовательно поднимаясь от каталога к каталогу вверх к корню сервера.
Так как
основные перемещения в Web-пространстве приходится все-таки делать по
гипертекстовым ссылкам (второй случай), то и выбор, который стоит перед
пользователем, это либо продолжить движение по ним, либо ознакомиться со
структурой каталогов сервера путем усечения адреса (URL-навигации), либо
использовать клавиши браузера для возврата к уже просмотренной странице.
Фактически
речь идет о том, что одновременно существует два логических уровня организации
информации ‑ путем размещения ее определенным образом в
иерархии каталогов, а также путем ее связывания с помощью гипертекстовых ссылок.
На
хорошем информационном узле, как правило, оба уровня
несут смысловую нагрузку, например, перейти к просмотру предлагаемых учебных
курсов по Интернет можно как по ссылке "Курсы об Интернет" на домашней странице
узла, так и при обращении по URL
"http://server.citmgu.ru/internet/cources".
Различия
в базовых структурах Web-узлов во многом строятся на существовании такой
двухуровневой системы навигации.
В
некоторых источниках принято различать плоскую, линейную, древовидную и комбинированную структуры.
Плоская
структура
предполагает, что в центр узла ставится головной документ, с которого имеются
ссылки на все остальные документы, те в свою очередь также могут ссылаться друг
на друга и на головную страницу. Ясно, что точкой отсчета для очередной
процедуры поиска-просмотра в этом случае является головной документ и требуется
определить наиболее быстрый доступ к нему с любой страницы, например, по
специальной ссылке на каждой странице, по закладке в браузере или по URL.
Структура
каталогов стоит здесь на втором плане.
Линейная,
или последовательная структура
связывает ряд документов, в каждом из которых предусмотрены только ссылки
вперед-назад. В чистом виде она встречается редко, и в этом случае перескочить
сразу через несколько пунктов
– но только назад, позволяет прямой выбор документа из списка просмотренных
страниц из истории браузера.
Следующая
‑ древовидная структура
гипертекстовых ссылок узла полностью повторяет логическую организацию его
каталогов, хотя это, разумеется, не означает, что каталоги и ссылки будут иметь
совершенно одинаковые названия. При этом эффективность URL-навигации заметно
возрастает.
Комбинированная
структура является
самой распространенной и предполагает совместное использование упомянутых выше
структур. Если переходы по гипертекстовым ссылкам после двух-трех первых
десятков просмотренных узлов ни у кого не вызывают затруднений, то URL-навигация
редко попадает в поле зрения пользователя, хотя при наличии древовидной
структуры документов она может превосходить по эффективности все другие виды
перемещений (например, каталоги Yahoo!). На Yahoo!, если вы получаете отклик на
поисковый запрос, а затем по гиперссылке попадаете в нужный раздел, усечение
адреса позволяет быстро переходить к более высоким уровням.
Чтобы
воспользоваться URL-навигацией на незнакомом узле, необходимо обратить внимание
на то, существует ли там какое-либо соответствие названий каталогов тематическим
разделам, заявленным в ссылках на домашней странице, т.е. при очередном шаге по
ссылке следует отследить изменение URL в адресном поле браузера.
Безусловно,
такие исследования оказываются практичными далеко не всегда, однако готовность
воспринять информационный узел в виде узнаваемой структуры помогает сэкономить
десятки секунд при работе с наборами документов, что в итоге выливается в
серьезное повышение производительности труда.
4.2. Логика "третьего" уровня и приемы применения автоматических поисковых средств.
"Третьим"
уровнем логики называют дизайн узла и типовое названия разделов, в которых
размещается информация заданного типа, а также со средства автоматического
поиска, применяемые на отдельной Web-странице и на узле. Все эти
вопросы тесно связаны между собой.
Домашняя
страница узла в большинстве случаев содержит в левой или верхней части экрана
основное меню, с которого идут ссылки на информационные разделы. В таких случаях
используются фреймы – специальных прямоугольных кадров на экране, в каждом из
которых может отображаться свой документ. При переходе по соответствующей ссылке
новый документ загружается в отдельный фрейм, а меню при этом остается на экране
нетронутым в своем фрейме. Если материал во фрейме не помещается целиком на
экране, то по умолчанию с правой стороны от него формируется полоса прокрутки. В
этом случае фрейм воспринимается как отдельное окно. Всякий раз полезно обратить
внимание на размер движка этой полосы, т.к. чем он меньше, тем большая доля
информации осталась за пределами экрана, а исходя из этого
можно принять то или иное решение об очередном шаге.
Если
информации хватает места, то полоски сбоку не возникает и выделить фрейм из
экрана становится трудно. При этом у многих пользователей появляются проблемы с
поиском и сохранением информации на локальный компьютер, поскольку для этого
приходится использовать простые, но все-таки специальные возможности браузеров,
а не те, что применяются при отсутствии фреймов.
Итак, на
сегодняшний день широко распространены два вида домашних страниц, а именно презентационная и
информационная.
Презентационная
страница, как
правило, насыщена графикой, имеет небольшое количество ссылок и помещается в
один экран. Ее задача ‑ представить компанию или учреждение в Интернет, которые
хотят заявить о сфере своей деятельности и указать возможности контактов.
Информационная
страница,
напротив, сводит к минимуму присутствие графических объектов и дает максимальное
текстовое наполнение, что увеличивает ее объем иногда до двух-трех и более
экранов.
Оба типа
страниц могут предваряться еще одной, так называемой страницей-заставкой,
обычно, почти чисто графической, которая загружается перед домашней страницей.
Ранее она часто использовалась для выбора кодировки на русскоязычных страницах,
однако теперь, когда эта проблема решается браузером автоматически,
необходимость в ней отпала, и она просто становится дополнительным препятствием
на пути к информации. Задача пользователя ‑ быстро пройти через нее, убедившись
в ее минимальной смысловой нагрузке.
Один из
самых эффективных способов ускорения работы с Web-страницей ‑ это активное
использование средств автоматического поиска, конечно, если вы знаете, что вам
нужно. Такой подход особенно практичен для многоэкранных страниц с
информационных узлов, когда визуальное ознакомление с материалом становится
слишком трудоемким.
Поиск на
странице можно произвести по терминам, введенным в специальный поисковый шаблон,
который активизируется в браузерах клавишами <CTRL>+F или через главное
меню "ПравкаàНайти
на
этой
странице" (Microsoft Internet Explorer) или "EditàFind in Page" (Netscape Navigator).
Работа
этих шаблонов несколько отличается в разных браузерах (рис 4.1) и имеет
некоторые особенности.
Рис. 4.1.
Шаблон для поиска на текущей странице в Internet Explorer
При
проведении процедуры поиска необходимо помнить следующее:
1.
Поиск
всякий раз проводится вверх или вниз по странице в зависимости от указания
направления в шаблоне (рис. 4.1) , начиная с начала (если вниз), или с конца
документа (если вверх), независимо от того, какая часть страницы отображается на
экране на момент начала поиска. Однако это справедливо только в том случае, если
на странице нет выделенных областей.
2.
Допустимо
введение в шаблон не только единичного термина, но и фразы, что делается одной
строкой без использования специального синтаксиса. Специальная пометка в шаблоне
позволяет искать с учетом регистра символов.
3.
Найденное
слово или фраза выделяются в тексте, и происходит автоматическое перемещение к
их местоположению, однако выделенное поле не всегда можно наблюдать. Сам шаблон,
остающийся на экране во время поиска может загораживать его (в этом случае надо
сместить шаблон мышью), кроме того, оно может быть отображено на экране не
целиком, а только его кромкой (следует использовать полосу прокрутки). Другими
словами, если нет сообщения о том, что поиск на странице завершен, то
обязательно необходимо обнаружить выделенное в тексте поле, иначе информация
будет потеряна.
4.
Если при
старте поиска уже есть выделенная область текста, то поиск начинается именно с
нее в заданном в шаблоне направлении, само содержимое выделенного поля участия в
поиске уже не принимает, также как и оставшаяся часть страницы. Отметим, что
всякий раз, когда поисковая процедура закончена, на странице остается выделенная
область текста, соответствующая последнему совпадению. Если необходимо выполнить
поиск с уже новыми терминами, то следует сначала снять уже существующее
выделение щелчком мыши в любой точке текста, иначе в новом поиске будет
участвовать только часть страницы вверх или вниз от выделенной области в
зависимости от направления, заданного в шаблоне.
5.
Надписи,
выполненные в графике, не откликаются на поисковые
запросы.
6.
Поисковый
шаблон браузера Netscape Navigator не имеет
возможности задать поиск термина как целого слова, как это позволяет сделать
Microsoft Internet Explorer. По умолчанию, если не выставлен нужный флаг, введенный в шаблон
термин, обнаруживает совпадения со всеми словами, в которые входит указанный в
шаблоне фрагмент, т.е. для термина "поиск" будут найдены совпадения со словами
"поиска", "поисковый" и т.п. Таким образом, поиск по странице в
Microsoft Internet Explorer имеет
дополнительную полезную функцию.
7.
Если при
проведении поиска экран разделен на фреймы, то браузеры работают по-разному.
Браузер Microsoft Internet Explorer
объединяет документы из разных фреймов в единое текстовое поле, в котором и
производит последовательный поиск после активизации пункта меню "Найти на этой
странице", т.е. автоматически переходит из фрейма во фрейм. Браузер Netscape Navigator имеет
специальную возможность поиска внутри заданного фрейма. При этом не следует
забывать о влиянии выделенных областей на работу программ.
В целом
для работы с фреймами Netscape Navigator несколько удобнее.
Так, например, узнать в нем о присутствии фреймов, если они не
просматриваются явно, можно, заглянув в меню в меню File, где сразу же
становятся доступными функции работы с фреймами (frames), также можно получить
более предметную информацию о фреймовой структуре и при просмотре источника
документа, однако для этого нужно знать язык HTML. Для операции с
документом во фрейме бывает нужно активизировать соответствующий фрейм щелчком
левой кнопки мыши по любой неактивной точке фрейма (т.е. не по гипертекстовой
ссылке, что спровоцирует немедленный переход). Если фрейм визуально не отличим
от остальной части экрана, следует выполнить щелчок мыши в области того
материала, который вас интересует.
Основное
меню узла, которое обычно расположено слева или вверху экрана, довольно часто
содержит надписи, которые выполнены в виде графики. Поэтому, как было указано
выше, нельзя локализовать термины из графического меню с помощью функции поиска
по странице. Однако, чтобы не лишать пользователя такой
возможности, часто разработчики дублируют заголовки графического меню в самом
низу домашней страницы в символьном режиме.
Обратиться
к финальным ссылкам, дублирующим графическое меню, бывает полезно и тогда, когда
само меню выглядит неудобно для чтения.
Глоссарий
терминов, соответствующих определенному типу информации, может отличаться в
зависимости от профиля изучаемых ресурс??в, поэтому пользователь, постоянно
решающий поисковые задачи, должен следить за обогащением своего словарного
запаса специфичной сетевой лексикой.
Специфика
этой лексики, базой для которой является естественный язык, связана с тем, что в
Сети доминируют авторы, имеющие техническое образование. Им свойственны лаконичность, колорит и тяготение к сленгу, во
многих случаях совершенно неоправданному. Разумеется, чем ближе профиль
материала к техническим проблемам, тем выше доля сленговой лексики. Так,
например, если сайт предназначен для представления программного обеспечения, то
раздел, содержащий новые поступления, скорее будет называться не "Новые
программы", а "Свежий софт".
На многих
серверах предусмотрена страница, которая предлагает еще более детальное
изложение его содержания, чем основное меню. Такая страница называется "Карта
сервера" ("Site map"). Если ссылка на нее присутствует на домашней странице и
приготовлена она не в виде графики, а виде обычного текста, то быстро найти ее
можно с помощью фразы-запроса "Карта сервера" ("Site map"), или иногда просто
"карта" ("map"). Если ссылка на нее не текстовая, а графическая, то
располагается она обычно либо в начале, либо в конце страницы, поэтому в случае
нулевого отклика на текстовый запрос, следует просмотреть именно начало и конец
страницы, а не приступать к немедленному чтению.
Аналогично
используют функцию поиска по странице для того, чтобы найти ссылку на локальную
поисковую машину, если она организована разработчиком узла. Тогда после нажатия
Ctrl+F следует ввести в шаблон слово "поиск" ("search"), и ссылка будет найдена
в течение секунды.
Для более
специализированных узлов целесообразно выработать собственную тактику выбора
значимых терминов. Еще раз хочется подчеркнуть, что важно не просто знать как то, что вы разыскиваете, называется по-русски или
по-английски, а как это называется в Интернет.
Отдельные
слова стоит сказать о специальных программах, которые могут быть внедрены прямо
в загружаемую вами страницу и написаны на языках Java, JavaScript, VBScript и
других. Обычно при старте таких программ в строке состояния браузера внизу
экрана возникает сообщение типа "Starting Java..". Об этом должен знать
пользователь, поскольку с помощью таких программных средств нередко задается
основное меню узла. Такие программы могут активизироваться по некоторому
событию, происходящему на экране, например, по движению мыши (даже без щелчка ее
кнопки).
Известно,
что при обращение к Web-серверу по протоколу http, если
загрузка происходит слишком долго, можно попытаться клавишей браузера
"Остановить", или "Stop" прекратить загрузку, а затем снова возобновить ее и
добиться от сервера более быстрого обслуживания. Если до остановки загрузки
часть информации с узла отобразилась, все гиперссылки в этом случае оказываются
работающими. Если вы не дождались окончания загрузки и нажали на появившуюся гиперссылку, то текущая загрузка прерывается
автоматически, но только в случае если новый документ открывается в том же окне.
Если же он открывается в новом, то происходит
одновременная загрузка двух документов: нового и старого, что замедляет передачу
каждого из них. Поэтому если старый документ перестал вам быть интересен,
необходимо нажать на "Остановить" ("Stop") до активизации очередного перехода.
Еще одно
замечание сделаем относительно возможности еще до нажатия на гиперссылку
отследить адрес (URL), по которому она осуществит переход. Когда указатель мыши
встает на ссылку (без нажатия), то в строке состояния браузера появляется
соответствующий адрес. Эту информацию можно использовать для предварительной
оценки целесообразности такого перехода, она также полезна и в случае применения
разработчиком специальной графической карты гипертекстовых ссылок (UsemapClient
Side), когда отдельные фрагменты сомкнутой воедино картинки, могут являться
ссылками на различные ресурсы.
Как правило, эти
алгоритмы поиска запатентованы, и поэтому встречаются только на коммерческих
сайтах (и то не на всех). Этот инструмент полезен для поиска
конкретного текста на сайте.
Аналог строки "Поиск по сайту"
имеется практически во всех специализированных каталогах и поисковых системах.
Они позволяют искать нужные ссылки внутри своего собственного каталога. При этом
в поиске участвуют не только тексты ссылок, но и аннотация ресурса в каталоге,
его тэги и другая метаинформация о ресурсе.
Если
информационное наполнение сервера меняется достаточно часто, то лучше
использовать локальный поиск с помощью специализированной поисковой
машины,
которая устанавливается на Web-сервер и индексирует только его. В числе таких
продуктов наиболее популярным является ЯndexSite компании CompTek.
4.3. Язык запросов ЯndexSite
ЯndexSite
представляет собой средство полнотекстового поиска информации на Web-сервере
с учетом особенностей морфологии русского языка. При установке ЯndexSite на главной странице формируется блок поиска по
серверу с возможностью вызова справочного материала для грамотного формирования
запроса, строки для ввода текста запроса и кнопки для начала запроса (рис.
4.2).
Рис.
4.2. Окно ЯndexSite
Язык
запросов, который используется в ЯndexSite повторяет
все основные правила формирования запросов в поисковой системы Яndex (учет
морфологии русского языка и больших букв, употребление знака "|", т. е. операции "ИЛИ", знака
тильда '~' и т. п.).
Результаты локального поиска
По
результатам поиска формируется список найденных документов (подобный Яndex). Для
каждого документа в списке указывается его заголовок, оформленный как
гиперссылка на найденный документ, приводится начало текста документа, дата и
URL документа, ссылающийся на оригинальный документ.
ЯndexSite
при индексации запоминает положение слова в документе, что дает возможность
выделить слова и словосочетания, найденные в тексте.
Слова
отмечаются особыми графическими элементами - красными угловыми стрелочками.
Если
запрошенное слово было найдено в заголовке, то оно выделяется там угловыми
скобками, а внизу выдается сообщение "Найденные в заголовке слова выделены
угловыми скобками".
Если
файлы были изменены, а индекс по ним не обновлен, об этом выдается
соответствующее предупреждение.
AltaVista (http://www.altavista.com/)
Поисковая система AltaVista (Альтависта),
начальная страница
которой представлена на рис. А.1, осуществляет поиск информации на 25 языках,
включая русский, осуществляет перевод найденных страниц
Интернет с английского на французкий, немецкий, итальянский, испанский или
португальские языки, а так же перевод с этих языков на английский. Возможен
поиск в группах новостей.
Поисковая машина AltaVista является
собственностью компании DEC - одним из крупнейших производителей компьютерной и
микроэлектронной техники. Использование AltaVista совершенно бесплатно как для
пользователей, так и для владельцев Web-сайтов, которые индексирует
AltaVista.
Одна из немногих выгод, которую
получает компания DEC, поддерживая дорогостоящую систему, - это реклама
собственной продукции. Так, компьютерный комплекс, на базе сервера AlphaServer,
который включает 10 процессоров Alpha - самых быстродействующих в мире с объёмом
оперативной памяти 6 Гбайт. Общий объём дисковой памяти составляет 210
Гбайт.
Сам же процесс индексирования
возлагается на поискового робота, который носит название "Scooter". Это
отдельный компьютер, который занимается тем, что ежедневно просматривает
несколько миллионов Web-страниц, составляет их индексы и корректирует базу
индексов. Особенностью AltaVista является, кстати, и то, что поисковый робот
просматривает абсолютно все страницы Интернета, которые он может найти, что,
конечно, позволяет данной поисковой системе выдавать наиболее полные ответы на
запросы, но обратной стороной является относительно редкое обновление индекса
для каждой из отслеживаемых Web-страниц. Тем не менее AltaVista - одна из лучших поисковых систем, которая
может быть рекомендована для российских пользователей
Интернета.
После ввода ключевых слов вы
получаете информацию о количестве найденных документов и их краткие описания со
ссылками на информацию в Интернете. Расширенный поиск позволяет использовать
логические операторы для формирования сложных запросов.
На начальной
странице кроме поля для ввода запроса расположена гиперссылка
Settings, открывающая
возможность установки различных параметров поиска (рис. А.2).
Рис. А.1. Начальная страница
поисковой системы AltaVista
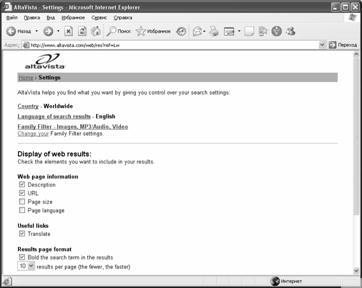
Рис. А.2. Окно
Alta Vista Settings
С его помощью можно
выбрать интересующий вас язык искомого документа: щелкните гиперссылку Language
of search results и в открывшемся окне выбора языка (рис. А.3) выберите Russian
(Русский) или любой другой язык из списка. По умолчанию ищется информация на
любом языке.
Выше поля ввода (рис.
А.1) расположены несколько ярлычков, щелчком на которых можно выбрать область
поиска: Web (Паутина) – во Всемирной паутине, News (Новости) – в группах
новостей и так далее.
Для поиска документов
содержащих некоторое слово, надо ввести это слово, а для поиска документов,
содержащих искомое словосочетание, необходимо заключить несколько слов в двойные
кавычки. Если слово содержит только строчные буквы, то ему сопоставляются также
и слова, содержащие заглавные буквы.
В системе «AltaVista»
можно задавать только часть слова, используя для этого метасимвол «*», который
заменяет от 0 до 5 букв. Использование этого знака похоже на его использование в
шаблонах файлов.
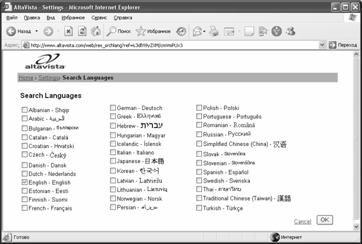
Рис. А.3. Окно выбора
языка поиска системы «AltaVista»
Другой удобной
возможностью является использование в запросах знаков + и -.
Добавив такой знак перед словом или фразой, вы требуете обязательное их
присутствие или отсутствие в документе. Если вы ставите знак + перед словом, то
этим вы указываете, что данное слово обязательно должно присутствовать в
найденном документе. Символ – указывает на то, что следующее за ним слово не
должно присутствовать.
Ещё одним удобным
способом уточнения поиска является использование специальных ключевых слов.
Существуют различные ключевые слова, мы рассмотрим только два наиболее полезных
слова. Ключевое слово link: позволяет ограничить поиск среди страниц, на которых
расположены ссылки на заданную страницу. Например, для поиска страниц со
ссылками на узел Microsoft, необходимо в качестве запроса ввести
link:www.microsoft.com.
Ключевое слово url:
позволяет искать среди страниц, в адресе которых существует заданная в качестве
аргумента часть. Если вы хотите найти все страницы, в адресе которых есть
название фирмы Intel, то следует ввести запрос url:intel. Эти ключевые слова
можно использовать вместе. Например, если мы хотим найти все страницы Российской
части Интернета, на которых имеются ссылки на систему «Alta Vista», следует в
качестве запроса указать link:altavista.digital.com
url:ru.
В подавляющем
большинстве случаев вы сможете найти необходимую информацию с помощью простых
запросов, но иногда могут потребоваться и более сложные.
Система «AltaVista»
позволяет формировать запросы с использованием логических операций. Они
называются сложными, или расширенными. Щёлкните мышью на ссылки Advanced Search
(Расширенные запросы), которая располагается справа от кнопки Find. Для
построения сложного запроса используются логические операторы и синтаксические
выражения.
Синтаксические
выражения – это любые слова и словосочетания, аналогичные рассмотренные в
простых запросах. Логические операторы служат для выполнения операций «И»,
«ИЛИ», «НЕТ» и «ОКОЛО» над синтаксическими выражениями. Часто синтаксические
выражения, над, которыми производятся логические операции, называются
аргументами. В синтаксических выражениях вы также можете использовать отдельные
слова или фразы, заключая несколько слов в двойные кавычки. Правила
использования заглавных и прописных букв в сложных
запросах так же не отличаются от данных правил в простых запросах. Главное, что
отличает сложный запрос – это использование логических операторов и круглых
скобок. С помощью операторов и скобок вы создаёте из отдельных синтаксических
выражений необходимый запрос.
С помощью элементов
управления, расположенных ниже поля для ввода условий поиска, можно задать язык,
дату и примерное расположение документа.
Ask Jeeves (http://www.ask.com/)
В Ask.com приоритеты
отдаются соответствию ссылки указанному ключевому слову. Ask.com используется
особый алгоритм индикации, основанный на соответствии предлагаемой информации.
Кроме того, в правой части страницы находятся подкатегории, которые позволяют
либо сузить, либо расширить зону поиска информации (рис.А.4).
Что касается перспектив
развития на 2007 год, то Ask.com планирует занять четвертое место по
популярности среди поисковых систем не только в США, но и в нескольких странах
Европы (Ask.com доступны во Франции, Италии, Германии, Нидерландах и Испании).
Если же говорить о долгосрочных перспективах, то в ближайшие 4‑5 лет Ask.com намерена составить конкуренцию
поисковой системе Google. Для того чтобы добиться намеченной цели, специалисты
намерены провести серьезную работу, направленную на то, чтобы изменить
стереотипы, сложившиеся у пользователей. Они полагают, что благодаря своему
опыту и умениям им удастся изменить привычки пользователей, привыкших прибегать
к услугам одной поисковой системы.
Ask.com имеет очень
простой интерфейс, однако это компенсируется наличием дополнительных функций,
которые могут существенно упростить процесс поиска информации. Так, например,
там имеется функция предварительного просмотра страниц. Кроме того, пользователь
может указать дополнительные параметры, согласно которым будет производиться
поиск информации, что позволяет не только сократить время, но и существенно
улучшить качество предлагаемой информации. Также следует отметить, что недавно у
поисковой системы Ask.com появилась новая функция автоматического перевода
страниц. Пользователи могут воспользоваться функцией автоматического перевода
страниц на французском, немецком, испанском и других языках на английский язык.
Кроме того,
специалистами в 2005 г. был запущен специальный сервис Blogs and Feeds,
предназначенный специально для поиска блогов, а так же подписки на блог.
Пользователи Ask.com могут производить поиск картинок и RSS-сообщений, а также
воспользоваться функцией расширенного поиска.
Разработчики поисковой
системы Ask.com выпустили новый тулбар, получивший название «Ask Toolbar».
Рис. А. 4. Начальная
страница поисковой системы Ask Jeeves
Помимо возможности
поиска информации в соответствующей поисковой системе, он позволяет сохранять
вэб-страницы, а также осуществлять поиск картинок и блогов. Кроме того,
благодаря специальной функции, Ask Toolbar выделяет в результатах поиска искомые
термины, тем самым, упрощая процесс поиска необходимой информации.
В
результатах поиска (рис. А. 5) представлены такие опции, как возможность
предпросмотра найденной страницы, возможность сохранения результатов поиска,
возможность подписки на найденный блог и возможность
хостинга. При вводе в поле
поиска слова на русском языке открывается возможность перехода на русскоязычные
поисковые системы.
Теперь у поисковой
системы Ask Jeeves можно узнать точное время в разных часовых поясах, спросить о
погоде, а также попросить помощи при пересчете различных величин. Например,
чтобы перевести
Рис. А. 5. Окно
поисковой системы Ask с
результатами поиска по слову на русском языке
Excite (http://www.exclte.com/)
Стартовав позже других
мощных систем - в конце 1995 года – поисковая система Excite (рис.
А.6) быстро завоевала популярность, поскольку
предлагает множество средств поиска в самых разных информационных средах. Среди
них - WWW, новости из электронных журналов и газет, E-mail адреса,
географические карты и атласы дорог, погода, котировки акций, а также такие
средства как поиск и резервирование мест в отелях, транспортных средствах и т.д.
Кроме того, Excite поддерживает несколько полезных служб, не связанных с
поиском, среди них - система общения в реальном времени Excite Pal, бесплатный E-Mail провайдер MailExcite, служба гороскопов и
многое другое. Каталог Excite содержит более 80 тысяч отобранных вручную ссылок,
представляющих лучшие Internet-ресурсы в большинстве областей человеческой
деятельности, каждая ссылка сопровождается кратким комментарием (3-4 строки).
Именно на Excite было впервые введено понятие тематических "каналов". Поисковая
машина Excite индексирует более 50 миллионов документов, индексация производится
по полному тексту. Среди всех зарубежных систем, Excite дает самую высокую
релевантность результатов для простого поиска. Это связано с тем, что в Excite
реализована уникальная эвристическая система обработки запросов Intelligent
Concept Extraction (tm) - по введенным ключевым словам Excite пытается
определить, что пользователь имел ввиду и ищет по
смыслу, а не только по словам. Благодаря этому, пользователь может получить
качественные результаты поиска, даже если искомые страницы не содержат введенных
ключевых слов. К сожалению, система эта работает только для английского языка и
является уникальной - российских аналогов не существует. Интересной особенностью
Excite является адресная реклама - рекламный баннер на
странице с результатами поиска зачастую связан с темой поиска. Возможности
расширенного поиска на Excite реализованы на базовом уровне. Помимо стандартных
логических операций над терминами, присутствует только ограничение области
поиска одной из категорий (3-4 региональных базы Excite, Usenet, News, WWW). С
помощью скобок и спецсимволов прямо в строке ввода на основной странице можно
ввести слова и фразы, которые должны присутствовать, должны НЕ присутствовать в
документе, альтернативные ключевые слова и тому подобное. Для тех, кто не хочет
разбираться в сложностях синтаксиса запроса, есть "Мощный запрос" ("Power
Query"), на страничке с которым можно построить свой запрос, выбирая условия и
логические операции из выпадающих списков. Excite вообще не поддерживает
русского языка. Очень интересной возможностью Excite является возможность
персонализации страницы.
Рис. А.6.
Стандартный вид начальной страницы поисковой системы Excite
FAST Search (http://www.alltheweb.com/)
Принадлежащий FAST
поисковик "понимает" 49 языков, умеет искать изображения, музыку в формате mp3,
индексирует и файлы в формате PDF. Цикл обновления документов в базе данных
составляет 7-11 дней.
История поисковика
AllTheWeb.com восходит к 1997 году, когда компания FAST Search & Transfer
была зарегистрирована в Норвегии. В 1998 году FAST открыла офисы в Бостоне и
Сан-Франциско. А уже в 1999 году были установлены партнерские отношения с Dell,
с целью создания самой большой базы данных проиндексированных web-страниц. Таким
образом, появилась поисковая система www.AllTheWeb.com,
которая имеет базу данных более 575 миллионов URL.
Но уже в феврале 2003
года, компания Overture покупает поисковик AllTheWeb, и в свою очередь
поглощается Yahoo в марте 2004 года.
В июле 2005 года
поисковая машина AllTheWeb.com (рис. А.7) обновила свой дизайн и функциональные
возможности. Этот ресурс просто незаменим, если требуется найти информацию по
необычной или малоизвестной тематике. Однако на нем отсутствуют многие
возможности, которыми обладают другие поисковые машины: например, он не умеет
автоматически распараллеливать свою базу данных для увеличения скорости поиска.
Одно из наиболее
заметных нововведений в поисковике AllTheWeb - это так называемый "универсальный
поиск", когда поисковая машина автоматически выдает информацию из разных
коллекций. Так, в дополнение к каталогу web-страниц AllTheWeb имеет базу
картинок, видеоклипов, MP3 и FTP-файлов из разных ресурсов Сети. При
осуществлении поиска результаты выдаются из всех этих
источников.
Следующее новый сервис
- интерфейс для поиска новостей. AllTheWeb News везде рекламируется как наиболее
быстрый: действительно, если ввести в поисковую форму
некое популярное словосочетание, вам представят результаты, которые попали в
базу всего одну минуту назад..
На AllTheWeb.com
можно точно указать, в какой именно базе производить поиск. Для этого следует
воспользоваться ссылками, расположенными под окном поиска или выбрать
соответствующую опцию на домашней странице AllTheWeb. Новый фильтр также
позволил решить проблему спама.
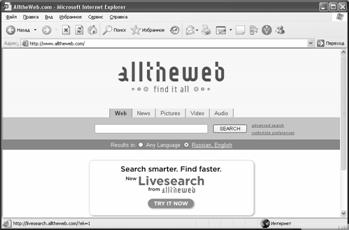
Рис. А.7. Начальная страница
поисковой системы AlltheWeb
Google (http://www.google.com/)
Google был запущен в 1998 году двумя аспирантами Стэндфордского университета
Сергеем Брином (Sergey Brin), выходцем из бывшего
СССР, и Ларри Пейджем (Larry Page), в свое время работавшими над учебным
проектом по идентификации смысловых элементов в структуре Web-ссылок. Они были
поражены огромным значением так называемых «обратных ссылок» (то есть страниц,
ссылающихся на сайт) и поняли, что их можно использовать для того, чтобы создать
более эффективную поисковую систему. Сначала поисковая система называлась
“Googol” (гугол), что означало число 10, возведенное в степень 100 (единичка со
ста нолями). Это подчеркивало бесконечное число документов в сети Интернет.
Однако, после того, как они представили проект своему
первоначальному инвестору, Брин и Пейдж получили чек на имя “Google”. Обдумав
сложившуюся ситуацию, через пару недель они решили открыть банковский счет на
имя компании “Google”. Причины успеха кроются в трех основных
положениях.
Первое – крайне релевантный алгоритм
поиска. В отличие от большинства поисковых систем Google не использует программы
с механизмом мета поиска. Она анализирует все содержание каждой web-страницы,
шрифт и место расположения всех заданных слов. В случае запроса фразой несущей
смысловую нагрузку, выдается ссылка на главную страницу сайта, посвященного
указанной теме. А не просто на статьи, содержащие отдельные слова из текста
запроса.
Второе - крайне дружелюбный к
пользователям интерфейс. Первая страница сайта поисковой системы Google
представляет собой практически чистое окно, не содержащее ничего кроме строки
поиска (рис.А.8). Это позволяет загружать его гораздо быстрее конкурирующих
поисковиков. Следуя современным традициям, Google разрешает любому познакомиться
с исходным текстом его программного обеспечения и предложить свои
улучшения.
Третье – поисковая система Google
подчеркнуто некоммерческий проект. Задумывался и создавался он без всякого
бизнес-плана, реклама никогда не была основной статьей доходов.
Google работает лучше, когда
требуется найти конкретную, специфичную информацию (например, «снегопады в
Швеции»), чем при абстрактных запросах (например, «собаки»), поскольку
результаты поиска не объединяются в категории, и при слишком широком запросе их.
Google располагает сайты в зависимости от содержания страницы и ключевых фраз в
заголовке и описании. Робот «читает» мета-тэги описания и ключевых слов,
учитывая популярность страницы, основанную на числе и значимости сайтов на нее
ссылающихся.
Эта поисковая система поддерживает
сотни форматов файлов, которые встречаются в сети: PDF, RTF, PostScript, Word,
Excel, PowerPoint и другие. Она просматривает и учитывает в своей базе данных
миллионы динамических страниц. Каждые 28 дней Google индексирует 3 миллиарда
веб-документов, в том числе более трех миллионов новых страниц каждый день.
Индексирование новостей позволяет получать последние заголовки информационных
агентств при поиске по «новостным» запросам. А самые
последние новости, найденные Google, всегда можно узнать по адресу: http://www.google.com/news/newsheadlines.html.
Google представляет
возможность не только работать в англоязычной среде, но и позволяет
открывать начальную страницу на национальном языке, например, http://www.google.
ru (рис. А.9).
Google не только упрощает доступ к
миллиардам веб-страниц, но и предлагает различные функции, позволяющие найти
именно то, что Вы ищете.
Сканируя Интернет, Google делает
снимок экрана каждой просмотренной страницы и сохраняет его в виде резервной
копии на случай, если исходная страница недоступна. Google использует
сохраненное в кэше содержание страницы на момент ее последней индексации для
оценки релевантности страницы относительно запроса поиска.
Google имеет свой калькулятора,
конвертер валют, возможность получать определение слова или фразы. Помимо HTML
страниц, в Google можно искать файлы в 12-ти других форматах (PDF, форматы
документов Microsoft Office, PostScript, Corel WordPerfect, Lotus 1-2-3 и многих
других). Google также предоставляет функцию "В виде HTML", позволяя
пользователям видеть содержание файлов в этих форматах, даже если у них не
установлена соответствующая программа. Эта функция также позволяет уберечься от
вирусов, которые иногда содержатся в файлах определенных
форматов.
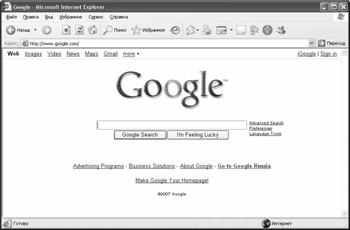
Рис. А.8. Окно поисковой системы
Google.com
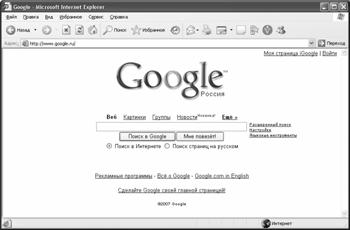
Рис. А.9. Окно поисковой системы
Google.ru
Иногда, выполняя поиск в Google,
можно увидеть результаты поиска из групп Google в нижней части страницы
результатов поиска. Это сообщения пользователей, опубликованные в группе
обсуждения по теме, связанной с запросом. Нажав на эти результаты, можно перейти
к полному тексту сообщения на сайте групп Google.
Кнопка "Мне повезет™" ведет прямо на
первую страницу, которую Google нашел по указанному запросу - Вы даже не увидите
других результатов поиска. Эта функция помогает тратить меньше времени на
поиск страниц и больше на их просмотр. Например, если
Вы ищете сайт Московского государственного университета, просто введите "МГУ" в
окно поиска и нажмите кнопку "Мне повезет!". Google перейдет непосредственно на
"www.msu.ru", официальный сайт университета.
В строке поиска Google можно вводить
идентификационные номера для отслеживания посылок, номера патентов и другие
специальные номера, чтобы быстро находить связанную с ними информацию.
При нажатии ссылки "Похожие страницы"
рядом с любым результатом поиска Google находит веб-страницы, похожие на этот
результат.
Программа проверки правописания в
Google автоматически проверяет, использована ли самая употребительная версия
написания запроса. Если по подсчетам программы получается больше значимых
результатов поиска с другим написанием, этот вариант будет предложен в сообщении
"Возможно, Вы имели в виду: (более распространенный вариант)?".
Используя технологии машинного
перевода, Google предоставляет пользователям доступ к веб-страницам, написанным
на иностранных языках. В настоящий момент поддерживаются
следующие языковые пары: английский - арабский, испанский, итальянский,
китайский, корейский, немецкий, португальский и французский, а также немецкий -
французский. Если в результатах поиска появляется страница на одном из
указанных выше языков, эта страница может быть мгновенно переведена при помощи
ссылки "Перевести эту страницу".
Google предоставляет различные
дополнительные сервисы, например, картографический сервис Google Maps —по адресу
http://maps.google.com/. Сервис представляет собой карту и спутниковые снимки
всего мира (а такжеЛуны). С сервисом интегрирован бизнес-справочник и карта
автомобильных дорог. Включающая в себя поиск маршрутов, охватывающая США,
Канаду, Японию, Гонконг, Китай, Великобританию, Ирландию и некоторые районы
Европы.
Сейчас поисковая система Google
регистрирует ежедневно около 50 млн. поисковых запросов и индексирует около 8
168 684 336 web-страниц. Google может давать информацию на 101 языке. На конец
августа 2004 года, компания состояла из 132 тыс. машин, расположенных в разных
точках планеты.
Lycos (http://www.lycos.com/)
В 1994 году Lycos начал развиваться
как самостоятельная поисковая система со своим собственным поисковым роботом. В
1998 году Lycos приобрел поисковую систему HotBot. Но летом 2000 года,
Lycos объявил, что больше не будет поддерживать своего
поискового робота и для выдачи результатов поиска будет использоваться
база данных FAST. Было также объявлено о заключении партнерских договоров с ODP
(DMOZ) и Direct Hit. Потом Lycos купил поисковую систему HotBot, но она была
оставлена как отдельный сервер, хотя некоторые изменения в алгоритмы поиска были
сделаны.
В октябре 2000 года Lycos был куплен
компанией Terra Networks, и стал ее подразделением, известным как Terra Lycos.
Lycos является старейшей из основных
поисковых систем. Помимо самой поисковой системы Lycos, имеет каталог A2Z и
рейтинг страниц «top 5% of all websites», некогда бывший очень популярным. На
данный момент Lycos не поддерживает свою базу данных, а использует базу данных
FAST, которая насчитывает более 600 миллионов проиндексированных страниц., Direct Hit и ODP (DMOZ), которая насчитывает 2 млн.
Lycos фактически использует тот же
алгоритм поиска, ту же базу, что и alltheweb.com. Свыше 625 миллионов
полнотекстовых страниц находятся в базе AlltheWeb, количество запросов к этой
поисковой системе составляет примерно 8 миллионов в день. Посетители могут
осуществлять поиск на 46 языках, в том числе русском, больше чем на
остальных поисковых системах.
Lycos, начальная страница которой представлена на рис. А.10, предлагает
достаточно много настроек поиска. Они доступны в разделе
"Расширенный поиск": http://lycospro.lycos.com/.
Это такие как поиск с использованием булевой логики (доступно: AND (+),
OR, NOT (-)), поиск фразы, поиск по расположение слов, поиск по месту
расположения слов, поиск в найденном, поиск не HTML файлов (изображения, видео,
mp3), многоязычная поддержка (24 языка, включая
русский).
Рис. А..11. Начальная страница
поисковой системы Lycos
Yahoo! (http://www.yahoo.com/)
В 1994 году, студенты
Стэндфордского университета, Джерри Янг и Дэвид Фило, готовились к защите
диссертации в области компьютерного проектирования интегральных схем. Для этого
им приходилось много времени проводить
в сети Интернет, в поисках нужной информации и копить ссылки. Списки со ссылками
росли, потом Янг и Фило забросили диссертацию и принялись исключительно
коллекционировать ссылки. К середине 1994 года их стало много, они отсортировали
ссылки по категориям, потом в категориях ссылок стало тоже много, появились
подкатегории.
Yahoo в 1999 году покупают поставщика
бесплатной электронной почты rocketmail.com. Таким образом Yahoo (рис. А.11) представляет из себя в первую
очередь портал (ранее – каталог сайтов с поиском по этому каталогу – аналогично
Rambler TOP100), предоставляющий любому все что он захочет, с очень хорошей
персонализацией (возможностью пользователю настроить сайт «под себя» и большим
количеством сервисов). Как таковой поиск Yahoo использует ядро поисковика www.overture.com
(компанию, которую он приобрел, чтобы качественно улучшить свой поиск). Сейчас
Overture в рамках корпорации Yahoo занимается разработкой системы контекстной
рекламы в поиске Yahoo.
Компания Yahoo!
анонсировала свою новую поисковую утилиту — SmartView. Когда пользователь
запрашивает информацию, она подключает поиск по всем службам Yahoo! — по
«Желтым страницам», «Кино», «Путешествиям» и прочим. Утилита позволяет
искать на карте различные объекты — отели, рестораны, автокинотеатры
и многое другое. Теперь пользователь может найти онлайн интересующий его
объект в любом городе США и Канады.
Рис. А. 11.
начальная страница поисковой системы Yahoo!
Но в
истории компании были не только взлеты. Первая публичная эмиссия акций Yahoo
состоялась в апреле 1996 года и совпала с началом бума дот-комов - количество
маленьких и больших интернет-компаний росло с каждым днем. Большая часть денег,
вырученных от IPO, была истрачена на рекламу портала. Ежегодный доход Yahoo
достиг 1 млрд. долларов США, а рыночная стоимость компании превысила 120 млрд.
долларов США.
Затем последовал крах
дот-комов. Выручка Yahoo сократилась на две трети, несколько кварталов подряд
были убыточными, рыночная стоимость компании упала до 4,6 млрд. долларов США.
Янг и Файло начали бороться за выживание. В мае 2001 года на место Кугла был
приглашен Терри Семел, который и вытащил Yahoo из кризиса. Портал стал
предлагать пользователям новые сервисы, причем за некоторые услуги взималась
плата. Yahoo возродился - объемы продаж выросли до 3,57 млрд. долларов США,
прибыль увеличилась до 840 млн. долларов США, а рыночная стоимость компании
поднялась до 50 млрд. долларов США.
Сегодня в спину Yahoo
дышат конкуренты, главный из которых - компания Google, которая, кстати, в пору
своего становления финансировалась именно фирмой Yahoo. Немного меньшую
опасность представляют Microsoft MSN и AOL, принадлежащий Time Warner. Янг и Файло относятся к этому
философски: "Люди не давали нам шансов еще десять лет назад. У нас всегда было
много конкурентов, однако сейчас наш будущий успех зависит только от нас".
В настоящее время
аудитория интернет-портала Yahoo насчитывает 345 миллионов человек, из них 165
миллионов являются зарегистриованными пользователями. Более 30 представительств
компании действуют в Северной Америке, Европе, Азии и тихоокеанском регионе.
В середине 2005 года,
компания Yahoo, официально объявила о достижении важного преимущества в борьбе
со своим главным конкурентом на рынке сетевого поиска — компанией Google.
Менеджеры считают, что поисковик Yahoo позволяет найти в два раза больше
документов, чем Google. По их мнению, база данных поисковой системы Yahoo
включает в себя 20,5 млрд объектов — 19 миллиардов
текстовых документов и 1,5 миллиардов изображений. Таким образом, ее поисковый
индекс (число объектов, которые пользователь может найти в интернете при помощи
поисковика), почти в два раза превышает аналогичный показатель поисковой системы
интернет-корпорации Google — 11,3 миллиардов объектов, из которых 8,2 миллиардов
текстовых документов и 3,1 миллиардов изображений.
Рис. А. 12. Начальное окно Yahoo
по-русскт
Go/Infoseek (http://www.go. com/)
Поисковый сервер
Infoseek начал свою работу в конце 1994 года. C 1999 он стал частью портала Go
(рис. А.13). Он предлагает такие услуги как персонализация доступа, бесплатную
электронную почту и возможности бывшей поисковой системы Infoseek. Также, портал
имеет очень большую базу данных сайтов, отобранных людьми.
Система является одной
из наиболее универсальных - создатели самостоятельно поддерживают индексы
WWW-страниц, сообщений UseNet, горячих новостей (по тематике), информацию о
компаниях и корпоративных новостей. Кроме того, поддерживаются: поиск
людей и даже пропавших
родственников, поиск географических карт и проч. Эти возможности интегрированы в
единый интерфейс, простой и понятный. Кроме того, на Infoseek находится очень
неплохой каталог (его разделы называются "каналами"), в котором можно найти
лучшие страницы по интересующей пользователя тематике. В хорошо продуманном
интерфейсе Infoseek легко разобраться и новичку. Помимо ссылок, связанных с
поиском и рекламой, есть довольно любопытный раздел "Достойно нажатия" ("Worth a
click"), в котором ежедневно дается несколько ссылок на
новые сайты с полезной информацией. Запросы можно
формулировать на естественном языке, правда, только на английском. При
вводе запроса на русском языке происходит переадресация на Yuhoo.ru. Одной из
особенностей формирования запроса является использование спецсимволов для
осуществления логических операций над терминами. Если ввести стандартные для
других поисковых систем слова-связки AND и OR, то Infoseek выведет миллионы
страниц, поскольку эти слова есть почти на каждой странице. Результаты поиска
выводятся в очень удобной форме - результаты с одного сайта сгруппированы
(выводится только один и появляется кнопка "другие результаты"), выводится
"процент релевантности", отражающий вероятность того, что данный документ
содержит необходимую информацию. Кроме того, в окне вывода результатов
отражаются не только результаты поиска, но и ссылки, нажатием на которые можно
провести поиск по ключевым словам в новостях, просмотреть связанные темы
(Related topics), а также настроиться на канал, освещающий данную тему. В форме
повторного поиска (Search again) есть полезная опция "искать только в уже
найденных результатах", которая позволяет уменьшить количество результатов
поиска, указав термины которые должны присутствовать или отсутствовать в новых
результатах. Поиск русских ресурсов на Infoseek работает посредственно. Во-первых, количество русских ресурсов,
проиндексированных InfoSeek'ом, довольно невелико. Во-вторых, никак не решается
проблема перекодировки из одной русской кодировки в другую. В индексе поисковой
машины Infoseek функционирует механизм удаления "мертвых" ссылок, количество
недействующих ссылок в результатах поиска очень мало.
Этот сайт входит в первую десятку по
посещаемости. Он является излюбленным местом в Интернете для «семейного чтения».
На сайтах InfoSeek также есть возможность бесплатного размещения домашних
страниц (Home Page Center), пейджинга и ведения дискуссий в on-line (chats).
Предлагаются и некоторые
дополнительные услуги, такие как ESP (Extra Search Precision) — для уточнения
поисковых запросов, а также аплет InfoSeek Desktop, позволяющий производить
поиск в Интернете прямо с рабочего стола Windows. Есть у InfoSeek и
локализованные версии, но русский язык в список поддерживаемых не входит.
Рис. А. 13.
Начальное окно поисковой системы Go/Infoseek
Hot Bot (http://www.hotbot.com)
Система запущена в мае 1996 года. В
октябре 1998 года Lycos купил Wired Digital, но продолжал поддерживать HotBot
как самостоятельный проект. В большинстве случаев источник первой страницы
результатов поиска HotBot (рис. А.14) - Direct Hit, а дальнейших - Inktomi.
Информацию для каталога берется из проекта Open Directory. HotВot находится в постоянной конкурентной борьбе с AltaVista.
Система индексирует более 55
миллионов страниц, получив начальную базу данных, краулер и систему поиска от
известной корпорации Inktomi. HotBot объединяет поиск различных видов данных и
различных ресурсов - UseNet, горячие новости, E-Mail адреса и проч. Однако при
этом используются базы данных других поисковых служб - сам HotBot поддерживает
только индексы по WWW страницам и мультимедийным файлам данных. В HotBot
сосуществуют поисковая машина и каталог. Многоцветный дизайн,
используемый на HotBot хорошо продуман - пользователь не "потерятся" на
странице. Для осуществления расширенного поиска нужно использовать гиперссылку
SuperSearch. По сравнению с Altavista, результаты простого поиска на HotBot
зачастую более релевантные и свежие, кроме того, за счет автоматического поиска
словоформ этих результатов по многим запросам несколько больше, чем на Altavista
и на Infoseek. Результаты с одного сайта, а также одинаковые документы с разных
"зеркал" объединены в одну группу, что существенно облегчает навигацию. Возле
каждого результата стоит число, которое показывает степень релевантности
результата теме поиска. В отличие от Altavista, все возможности поиска
реализованы с помощью полей ввода и выпадающих списков, а не с помощью
специального языка, поэтому составление сложных запросов для HotBot более
доступно для начинающего пользователя. Среди них такие возможности как включение
и исключение ключевых слов и фраз в поиск, ограничения по дате и типу документов
(например, только аудиофайлы), локализация поиска (определенный домен или
сервер) и проч. Скорость HotBot несколько ниже чем у
Altavista или Infoseek, иногда сервер даже не отвечает 15-20 секунд, поэтому
сложный поиск, когда производится неоднократное уточнение ключевых слов и
повторный поиск, может затянуться. Одним из основных недостатков HotBot является
отсутствие поддержки русских ресурсов, поэтому в индекс попадают только
документы на европейских языках.
Рис. А. 14. Начальное окно поисковой
системы Hot Bot
Яndex (http:// www.yandex.ru/)
История компании "
Яndex" началась в 1990 году с разработки поискового
программного обеспечения в компании "Аркадия". За два года работ были созданы
две информационно-поисковые системы - Международная Классификация Изобретений, 4
и 5 редакция, а также Классификатор Товаров и Услуг. Обе системы работали
локально под DOS и позволяли проводить поиск, выбирая слова из заданного
словаря, с использованием стандартных логических операторов. Один из
основателей Яндекса, Илья Сегалович
В 1993 году "Аркадия"
стала подразделением компании CompTek. В 1993-1994 годы программные технологии
были существенно усовершенствованы благодаря сотрудничеству с лабораторией
Ю. Д. Апресяна (Институт Проблем Передачи Информации РАН). В
частности, словарь, обеспечивающий поиск с учетом морфологии русского языка,
занимал всего 300Кб, то есть целиком грузился в оперативную память и работал
очень быстро. С этого момента пользователь мог задавать в запросе любые формы
слов (рис. В.1).
Слово "Яndex" придумал за несколько лет до этого один из основных и
старейших разработчиков поискового механизма. "Яndex"
означает "Языковой index", или, если по-английски, "Yandex" - "Yet Another
indexer". За 4 года публичного существования Яndex
возникли и другие толкования. Например, если в слове "Index" перевести с
английского первую букву ("I" - "Я"), получится "Яndex".
В начале 1996 года был
разработан алгоритм построения гипотез. Отныне морфологический разбор перестал
быть привязан к словарю - если какого-либо слова в словаре нет, то находятся
наиболее похожие на него словарные слова и по ним строится модель
словоизменения.
Рис. В. 1. Окно
первой версии сайта Яндекса, изготовленная А.
Лебедевым.
Еще через полгода
стало очевидно, что ничто не отделяет CompTek от создания собственной глобальной
поисковой машины. Объем Рунета составлял тогда всего несколько гигабайт. Осенью
1997 года был открыт Yandex.Ru, начальная страница которого представлена на рис.
В.2.
Рис. В. 2.
Начальная страница поисковой системы Яндекс
Яндекс предлагает
по адресу ya.ru возможность
использования короткой строки (рис. В.3).
Рис. В. 3.
начальная страница поисковой системы Яндекс с использованием короткой строки
Сегодня Яндекс -
это крупнейший российский портал, предлагающий пользователям ключевые веб-службы. Ежедневная
аудитория Яндекса - более четырех миллионов человек. Яндекс представляет
собой рекламную площадку с возможностями как широкого
охвата аудитории, так и точно сфокусированной рекламы.
Рамблер (http://www.rambler.ru/)
В 1991 году в
подмосковном научном городке Пущино появилась группа единомышленников.
Вдохновленная только что появившейся коммуникационной средой интернет, группа
активно занималась внедрением сетевых технологий в бизнес-среду. Через пять лет,
в 1996 году, программист Дмитрий Крюков написал первую уникальную российскую
поисковую программу, которая сразу же была запущена в эксплуатацию. Название
Rambler переводится как "бродяга, странник, скиталец". Так появилась
информационно-поисковая система Rambler, а 3 марта 1997 года заработала
рейтинговая система Rambler's Top100, которая с момента своего существования и
по сей день считается лучшим классификатором российского интернета и пользуется
репутацией независимого арбитра российского интернет-рынка. На базе этих двух
проектов - поисковика и рейтинг-классификатора - был выстроен портал "Рамблер" в
том виде, в каком мы все его знаем (рис. В. 4).
Рис. В. 4. Окно поисковой системы
Rambler
Позже на Рамблере
появились новости, бесплатная почта для пользователей и множество других
популярных проектов. Каждый год истории Рамблера была ознаменована новыми
достижениями. В
В июне
В начале 2006 года
Rambler Media - группа компаний, владеющая порталом Рамблер - приобрела
контрольный пакет акций ведущего оператора электронной торговли России -
компании "Прайс Экспресс". В ее состав входят такие известные площадки, как
Price.Ru и Тындекс.Ru.
2006 год закрепил
позиции Рамблера как активного игрока интернет-рынка. Рамблер приобрел 51%
"Прайс-Экспресс", ведущей российской компании в сфере электронной торговли. Были
куплены активы проектов "Баннербанк". Группа компаний Rambler Media, владеющая
интернет-холдингом Рамблер, объявила о создании на базе действующего сайта
газеты "Из рук в руки" нового информационного портала. Договоренность о таком
проекте была достигнута с компанией Trader Media East, владеющей газетой "Из рук
в руки".
Юбилейный год
принес Рамблеру и очередное признание его заслуг: 2 февраля, на церемонии
вручения награды "Супербренд 2005", Рамблер получил титул одной из самых сильных
и узнаваемых торговых марок современной России, а 20 февраля группа компаний
Rambler Media была включена в новый экономический Индекс привлекательности
российских компаний за рубежом (RUXX).
Апорт
(http:// www.aport.ru/)
Старейшая
русскоязычная поисковая система (с
В ноябре 1998 года
Aport был продан гражданину Израиля Джозефу Авчуку. Сумма сделки составила 55
тысяч долларов. Торговые марки "Апорт" и "Агама" сохранились, каталогу Ау! повезло гораздо меньше. В 1999 году Авчук окончательно
покупает каталог и переименовывает его в AtRus, а после и вовсе уничтожает при
экспорте на сайты "Омен", "Россия он-лайн" и "Апорт".
Конец 1999 года -
в поисковую систему Апорт вложен первый миллион долларов, это позволило,
некоторое время спустя, представить на компьютерных выставках "Апорт - 2000".
Полностью интегрированный с AtRus; теперь Каталог - Апорт (Catalog -
Aport).
Поисковая система
Aport 2000 (рис. В. 5) была построена на основе выдачи результатов по отдельно
взятым сайтам. Для разделения ресурсов на сайты Апорт
использует информацию, которую предоставляет каталог AtRus, или владельцы
ресурсов.
Рис. В. 4.
начальное окно поисковой системы Апорт
Www.aport.ru -
первым из поисковых систем Рунета реализовал базовые технологии Google. "Page
rank" - характеристика популярности ресурса по формуле "обратных ссылок": ссылки
с других сайтов на данный ресурс. Причем учитывается не только количество, но и
важность ссылок. Вес ссылки с популярного сайта больше, а ссылки включающие
слова запроса ценятся выше, чем ссылки со словом "здесь". К тому же, при
обработке запроса поисковая система Aport 2000 ориентируется на HTML - код
страницы, и наличие слов запроса в URL.
Апорт предлагает
по адресу au.ru возможность
использования короткой строки (рис. В.5).
Рис. В. 5.
начальная страница поисковой системы Апорт с использованием короткой строки
Первым
www.aport.ru стал использовать платную нулевую строку в выдаче (контекстная
реклама). Но на Апорт купить не нулевое, просто более высокое место в ответной
странице.
31 июля 2000 года
Golden Telecom купил семейство интернет-проектов "Агама", включающее "Апорт" и
AtRus, для включения в "Россию-он-лайн" и околоконтентные
проекты.
В мае 2001 года
окончательно завершилась сделка по смене владельца "Апорт" самого "Golden
Telecom", новым владельцем стал "Альфа-Банк". NASDAQ к тому времени переживал
бурный спад, и шансов перепродать Интернет проекты за приемлемую сумму не было.
Это обусловило решение новых хозяев "Golden Telecom" минимизировать расходы на
поддержку дорогостоящих Интернет проектов.
ВебАльта (http:// www.webalta.ru/)
Российская IT-компания основана 25 августа 2005
года участниками форума umaxforum.com, которые зарабатывали на конвертации
трафика (дорвеи, поисковый спам, PPC-системы).
Компания специализируется на
разработке инновационных решений в области поиска информации, интернет-рекламы и
развлечений. Ключевой проект компании - поисковый сервис Webalta (рис. В.
6).
Рис. В. 5.
Начальная страница поисковой системы ВебАльта
Созданный специалистами компании на
основе открытых технологий и ряда оригинальных разработок поисковик Webalta
проиндексировал, по состоянию на декабрь 2006 года, 765 634 061 документ объемом
19 920 Гигабайт. На стадии публичного тестирования поисковую машину
ежедневно посещают порядка 50 000 пользователей, делающих в неделю более 500 000
переходов на другие сайты. В планах основателя и генерального директора Вебальты
Алексея Гурешова "завоевать" 30% аудитории Рунета к 2008
году.
Одной из уникальных инноваций,
созданных специалистами компании, является публикуемый Webalta индекс Уровня
доверия к сайтам. Помимо входящих ссылок и цитат,
индекс учитывает и множество других факторов, вплоть до времени регистрации
доменного имени и репутации компании, на чьих серверах физически размещены страницы сайта. На ранжирование документов в выдаче
оказывает влияние посещаемость сайта, которую Вебальта узнавает с помощью
тулбара и кнопки рейтинга.